7 Analyser un corpus
Les outils d’analyse de TXM sont lancés par le biais de commandes de menu ou de barre d’outils qui s’appliquent à des objets (corpus, sous-corpus, partition…) ou des résultats (index, concordance…) sélectionnés dans la vue Corpus.
L’objet n’a pas besoin d’être sélectionné si l’outil est lancé depuis son menu contextuel (accédé par un clic droit sur l’objet).
Les outils de TXM peuvent également être lancés entre résultats par le biais de liens hypertextuels au sein des fenêtres de résultats.
En général les outils ouvrent une nouvelle fenêtre qui permet de paramétrer, lancer et parcourir le résultat du calcul.
Un calcul peut être interrompu en appuyant sur le bouton « Cancel » de la fenêtre de progression.
7.1 Propriétés des objets TXM
L’outil Propriétés fournit des informations détaillées sur tous les objets de TXM.
Pour les résultats de calculs, il s’agit :
- des valeurs de paramètres utilisées ;
- de statistiques générales sur les résultats.
Pour les corpus et les partitions il affiche des informations spécifiques.
La figure 7.1 montre un exemple de propriétés de corpus.
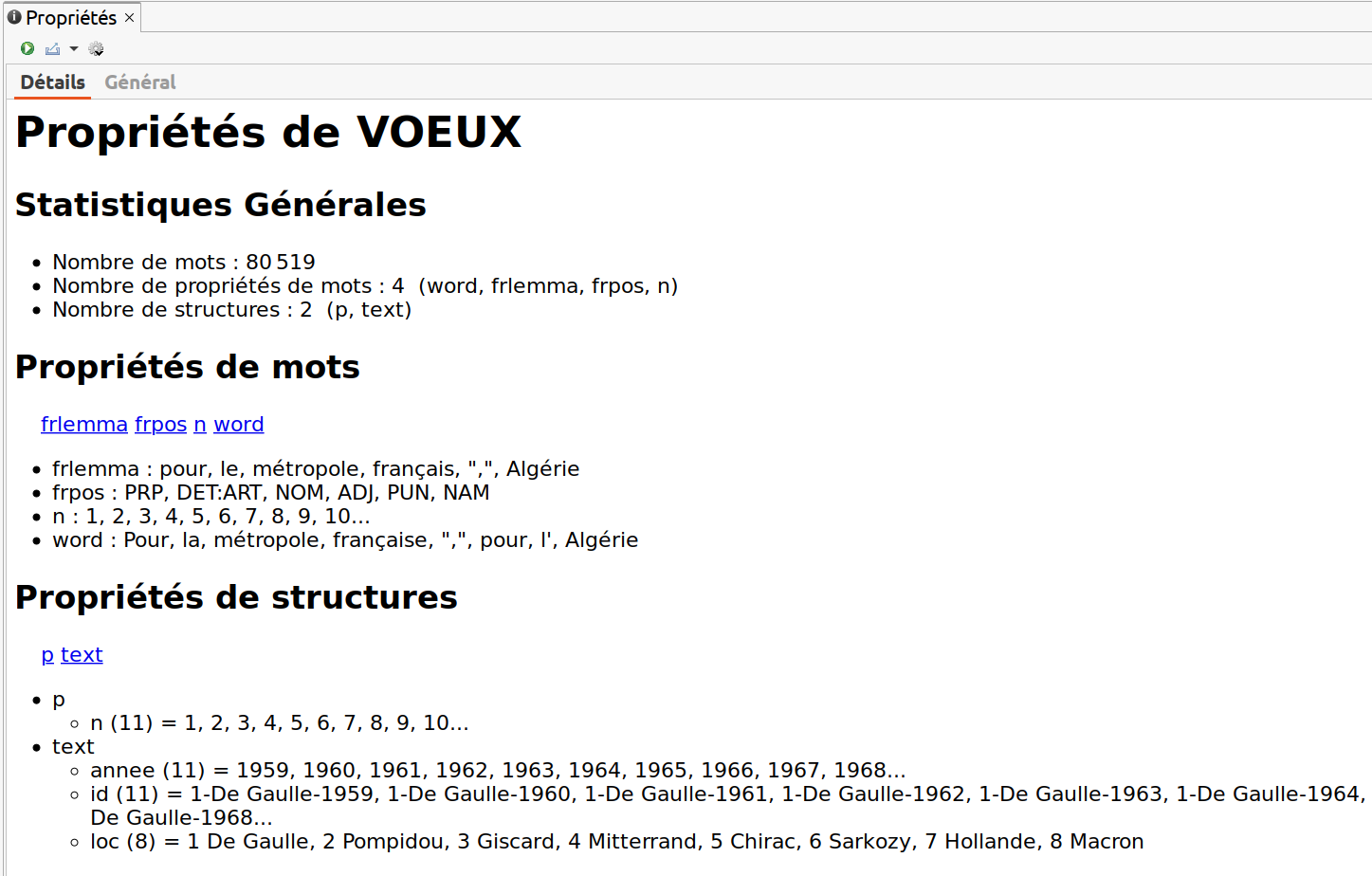
Figure 7.1: Onglet ‘Détails’ des propriétés du corpus VOEUX.
7.1.1 Appliqué à un corpus ou à un sous-corpus
Cet outil affiche deux ou trois onglets :
- « Détails » (affiché par défaut) : présente une synthèse complète de la composition du corpus et des statistiques générales
- « Général » : affiche les propriétés techniques, la description et le journal du corpus
- « Documentation » (optionnel) : affiche la documentation du corpus (si elle est présente dans le corpus)
7.1.1.1 Paramètres :
- V max : nombre maximal de valeurs affichées
- par défaut 20 valeurs maximum de propriétés de mots ou de structures sont affichées
- Longueur de ligne maximum : longueur maximum d’une ligne de liste de valeurs (en caractères)
- par défaut les lignes sont tronquées à 200 caractères.
7.1.1.2 Onglet « Détails »
- Statistiques générales
- le nombre total de mots - ou « unités lexicales » ou « tokens »
- tels que calculés à l’import du corpus dans TXM. Les mots ont pu être calculés et pré-encodés par des outils externes en fonction du format source et du module d’import utilisé
- la liste des propriétés de mots et leur nombre (forme graphique - word, frpos, frlemma, etc.)
- frpos, frlemma sont calculés en général à l’import du corpus dans TXM mais comme d’autres propriétés peuvent être calculées par des outils externes en fonction du format source et du module d’import utilisé
- la liste des structures internes aux textes et leur nombre (text, div, p, etc.)
- les structures sont souvent encodées en amont avant l’import dans TXM dans des sources au format XML
- Propriétés de mots
- pour chaque propriété, les premières valeurs prises au fil du corpus
- Propriétés de structures
- pour chaque structure
- pour chaque propriété
- les premières valeurs prises au fil du corpus
- pour chaque propriété
La figure 7.1 montre un exemple de détails des propriétés du corpus VOEUX.
7.1.1.3 Onglet « Général »
Affiche les propriétés techniques du corpus :
- Nom : le nom du corpus
- Chemin : le chemin du corpus dans l’arborescence des résultats de TXM
- Dossier : le chemin du dossier contenant la version interne du corpus
- Date de création : date d’import du corpus
- Date de dernière modification : date de dernière mise à jour du corpus
- Description : champ de description libre du corpus, que l’utilisateur peut éditer (format HTML). Pré-rempli au moment de l’import
- TXM Version : version de TXM ayant fait l’import du corpus
- Journal : liste des différents évenements du cycle de vie du corpus, que l’utilisateur peut éditer (format texte brut)
La figure 7.2 montre un exemple de propriétés techniques du corpus VOEUX.
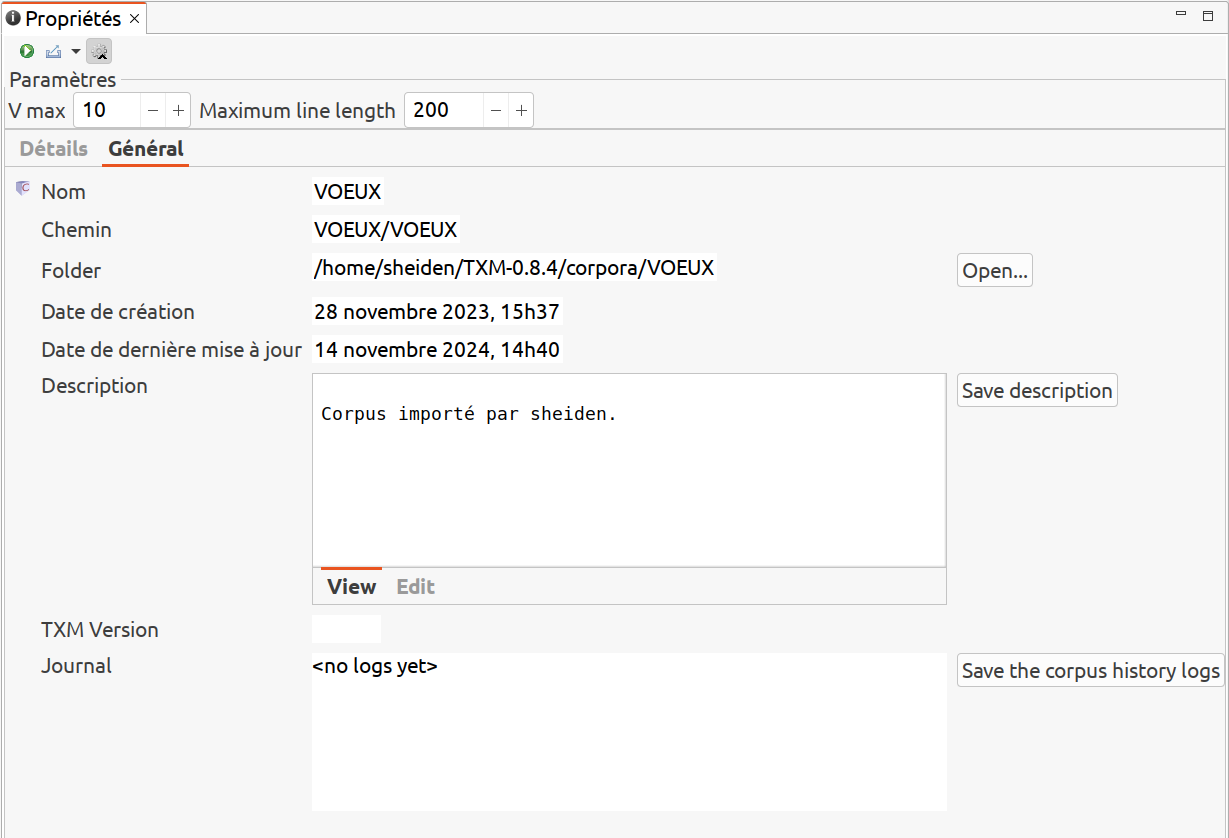
Figure 7.2: Onglet ‘Général’ des propriétés du corpus VOEUX.
7.1.1.4 Onglet « Documentation »
Affiche la documentation du corpus sous la forme d’une page HTML si elle est présente dans le corpus.
Remarque : Pour ajouter une documentation à un corpus, il suffit de déposer un fichier index.html (et d’éventuels fichiers annexes : pages html annexes pointées par l’index, images, etc.) dans un dossier ‘doc’ du dossier contenant la version interne du corpus (voir le champ “Dossier”).
7.2 Édition : lecture d’un texte
La commande Édition affiche la première page de l’édition du premier texte du corpus sélectionné. Le préambule de l’édition, situé en haut de la première page, affiche toutes les métadonnées du texte.
Dans cette édition, on peut naviguer :
entre pages du texte courant :
page suivante «
 » ou page
précédente«
» ou page
précédente«  » ;
» ;directement à une page donnée «
 » ;
» ;à la fin du texte «
 » ou au début du
texte «
» ou au début du
texte «  » ;
» ;
entre textes du corpus :
texte suivant du corpus «
 » ou texte
précédent «
» ou texte
précédent «  ».
».dernier texte du corpus «
 » ou premier
texte «
» ou premier
texte «  ».
».
Une autre façon d’accéder à l’édition se fait par retour au texte depuis une concordance. Double-cliquer sur une ligne de concordance (voir ci-dessous) vous mène directement à la page concernée de l’édition, où le pivot de la concordance sera surligné en rouge (s’il y a plusieurs occurrences de la requête dans la même page de concordance, elles seront surlignées en rouge clair).
La figure 6.31 présente la première page de l’édition du premier texte du corpus VOEUX:
dans cet exemple, les métadonnées sont : loc et annee
loc : nom du locuteur
annee : l’année au format 0000 des voeux prononcés
chaque mot peut être survolé avec la souris afin d’afficher ses propriétés dans une infobulle : pos, func, lemma
dans cette exemple, la souris est placée sur le mot « je », l’infobulle affiche :
- frpos = « PRO:PER » pronom personel
- frlemma = « je »
- n = position du mot dans le corpus
- w_1DeGaulle1959_14 : identifiant unique du mot dans le corpus
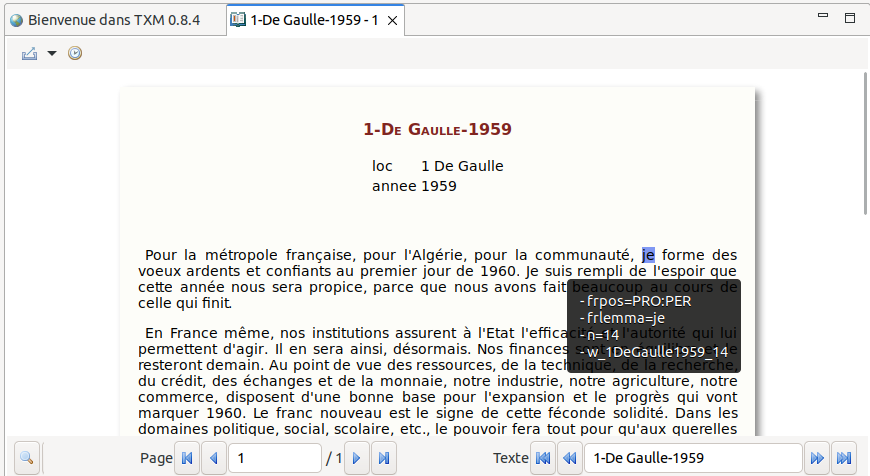
Figure 7.4: Première page de l’édition du premier texte du corpus VOEUX.
7.4 Lexique et Index
Les listes de mots peuvent être obtenues via deux commandes complémentaires :
Lexique : calcule la liste hiérarchique de toutes les valeurs d’une propriété de mot donnée d’un corpus ou sous-corpus (la fréquence de chaque forme graphique, de chaque lemme, etc.) ;
Index : calcule la liste hiérarchique des combinaisons de valeurs de propriétés correspondant aux occurrences d’une requête CQL cherchée dans un corpus ou un sous-corpus (la fréquence de chaque lemme de substantifs, des formes graphiques des occurrences de la séquence « Adj Subst », etc.).
7.4.1 Lexique
La commande Lexique calcule la liste des fréquences de toutes les valeurs d’une propriété lexicale donnée pour un corpus ou un sous-corpus (par exemple : les formes de mots, les étiquettes morphosyntaxiques, les lemmes, etc). Par défaut, à l’ouverture, la commande calcule le lexique de la propriété lexicale « word » (celui des formes). Le résultat se présente sous forme d’un tableau :
Vous pouvez trier le tableau sur chaque colonne en cliquant sur son entête (tri sur les formes ou tri sur les fréquences). Un clic supplémentaire inverse l’ordre de tri.
Vous pouvez exporter ce tableau au format CSV, voir la section 6.15.1.1 Export des tableaux page 125.
7.4.2 Index
La commande Index calcule la liste de fréquences des valeurs de propriétés des occurrences d’une requête CQL donnée pour un corpus, sous-corpus ou une partition.
7.4.2.1 Choix du jeu de propriétés de mots à lister
Les occurrences sont décomptées en fonction des valeurs des propriétés de mots sélectionnées. Comme pour le lexique, par défaut ce sont les formes graphiques des occurrences de la requête qui sont listées et décomptées (« word »).
TXM permet non seulement de construire la liste à partir des autres propriétés de mots - catégories grammaticales, lemme et de façon générale, toute propriété de mots encodée dans le corpus - mais également de les combiner.
On peut sélectionner le jeu de propriétés à combiner avec le bouton « Éditer »[47] :
Sélectionner dans la liste de gauche les propriétés que l’on souhaite ajouter[48]. Faîtes les basculer grâce aux flèches qui permettent d’ajouter ou de retirer les propriétés :
«
>» : permet d’ajouter une propriété (on peut aussi double-cliquer sur une propriété dans la liste de gauche) ;«
<» : permet de retirer une propriété (on peut également double-cliquer sur une propriété dans la liste de droite) ;«
^» : permet de modifier l’ordre d’une propriété vers le haut (la propriété qui se trouve tout en haut sera celle qui s’affichera en premier) ;«
v» : permet de modifier l’ordre d’une propriété vers le bas.
7.4.2.2 Requêtes
Vous pouvez utiliser les mêmes requêtes CQL que pour les concordances (ainsi que l’assistant de requêtes).
Le résultat se présente sous forme d’un tableau :
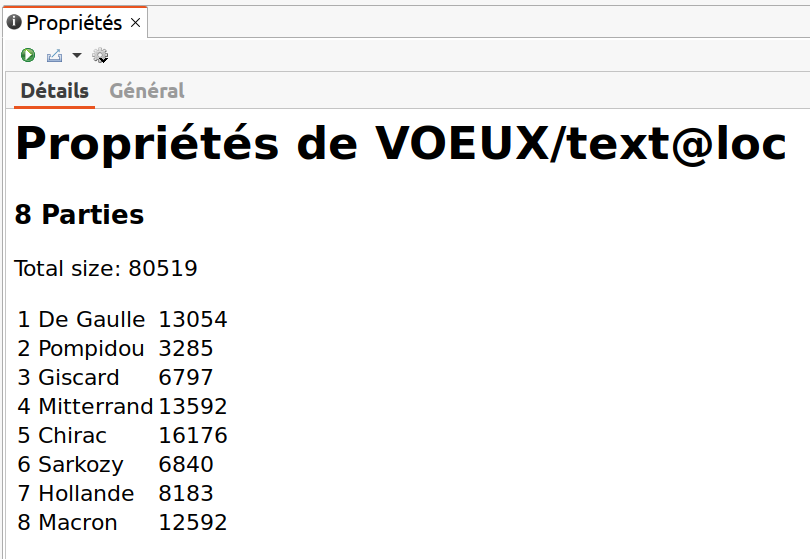
7.4.2.3 Index d’une partition
L’Index appliqué à une partition calcule le tableau des fréquences ventilées par parties. Ce tableau peut alors être transformé en une Table lexicale pour être soumis au calcul des Spécificités, AFC ou CAH.
7.4.2.4 Filtrage des résultats
Vous pouvez élaguer les résultats avec les seuils suivants :
Fmin : fréquence minimum à partir de laquelle on ajoute un résultat à la liste ;
Fmax : fréquence maximum ;
Vmax : nombre maximum de résultats à afficher. Par exemple si Vmax = 100, on obtiendra les 100 premières valeurs triées par la fréquence ;
Résultats par page : nombre de résultats par page.
7.4.2.5 Navigation dans les résultats
L’index affiche d’abord la première page de résultats.
Vous pouvez naviguer dans l’ensemble des résultats avec les boutons suivants :
« » : page des résultats ;
«
 » : page précédente ;
» : page précédente ;«
 » : page suivante ;
» : page suivante ;«
 » : dernière page.
» : dernière page.
7.4.2.6 Appel de commandes à partir des résultats
La commande index est liée aux commandes Concordance et Progression.
Vous pouvez sélectionner certaines lignes de l’index avec la souris[49], puis par l’intermédiaire du menu contextuel, choisir la commande à exécuter :
« Envoyer vers la concordance » : une requête CQL correspondante sera créée afin de construire la concordance.
« Envoyer vers la cooccurrence » : une requête CQL correspondante sera créée afin de construire une cooccurrence.
« Envoyer vers la progression » : autant de requêtes CQL que de lignes sélectionnées seront créées pour construire une progression.
Vous pouvez exporter ce tableau au format CSV, voir la section 6.15.1.1 Export des tableaux page 125.
7.5 Concordances
Cette commande construit une concordance kwic des occurrences d’une requête CQL dans un corpus ou dans un sous-corpus.
L’affichage prend la forme suivante (voir illustration Illustration page 90) :
toutes les occurrences sont affichées verticalement dans la colonne « Pivot »
chaque occurrence est affichée sur une seule ligne avec les mots qui la précèdent « Contexte gauche » et les mots qui la suivent « Contexte droit » ;
la première colonne du tableau de concordance « Références » permet de situer l’occurrence ;
le contenu de chaque colonne peut être adapté à l ’aide de nombreuses options d’affichage et de tri ;
le tableau de concordance est paginé.
La zone des paramètres est organisée de la façon suivante :
un champ pour saisir la requête CQL ;
un bouton pour accéder à l’historique des requêtes ;
le bouton pour lancer le calcul.
le bouton « Afficher/Masquer les paramètres de commande »: affiche ou cache les paramètres de la concordance pour améliorer le confort de lecture.
7.5.1 Requêtes CQL
Le moteur de recherche vous permet d’exprimer les recherches dans le langage CQL (pour « Corpus Query Language », voir ci-dessous la section 5 « la syntaxe du moteur de recherche »).
TXM utilise une syntaxe simplifiée basée sur le langage CQL, afin d’écrire facilement des requêtes. Par exemple, pour rechercher la mot « je », vous n’avez qu’à écrire « je » dans le champ « Requête ».
Pour des recherches plus complexes, vous pouvez utiliser toute la variété du langage CQL. Par exemple, pour chercher :
le mot « je » suivi d’un verbe
dans le corpus DISCOURS, vous pouvez saisir la requête suivante :
“je” [pos=“V.*”]
Cette requête peut être décomposée ainsi :
“je” désigne le mot « je » ;
[pos=“V.*”] indique que le verbe sera sur la droite du mot « je » :
les crochets […] indiquent qu’il ne doit y avoir qu’une seule unité lexicale à la droite du mot « je » ;
pos=“V.*” indique que l’occurrence doit porter l’étiquette morphosyntaxique « V.* ». Dans le corpus DISCOURS, étiqueté par Cordial et le jeu d’étiquettes Multext, cette requête sélectionne tous les verbes (dans ce corpus, tous les verbes ont une étiquette qui commence par « V »).
7.5.1.1 Assistant de requêtes CQL
Il est possible de construire les requêtes à l’aide d’un assistant. Un clic sur l’icone « Assistant de Requête » ouvre la fenêtre de l’assistant :
La requête est construite en choisissant des propriétés de mot à contraindre et leur valeur dans des « expressions de mot ».
Par exemple :
la propriété « word » (pour la forme graphique) du mot « correspond à » la chaîne saisie dans le dernier champ (par exemple « je ») ;
la propriété « frpos » (pour sa partie du discours) du mot « commençant par » « V » (pour chercher tous les verbes).
L’assistant permet d’exprimer une succession de mots à l’aide du bouton « Mot supplémentaire » qui ouvre une « expression de mot » supplémentaire pour exprimer les contraintes sur le mot suivant à rechercher. Le menu situé entre les expressions de mots permet de préciser si les mots sont adjacents (« suivi de ») ou non.
On peut éventuellement marquer un des mots de la requête pour le mettre en évidence dans les lignes de concordances ou pour focaliser un index (construire l’index à partir des propriétés de ce mot seulement).
Pour limiter le contexte de la recherche, il faut activer le champ « dans un contexte de ». On peut régler la taille du contexte en nombre de mots ou en nombre de structures.
On termine l’assistant avec le bouton « OK », ce qui insère la requête CQL correspondante dans le champ « Requête ».
Pour lancer la recherche, cliquer sur le bouton .
Avant d’afficher les résultats de la concordance, la zone de commentaires ainsi que la ligne de statut vous donneront le nombre total de résultats.
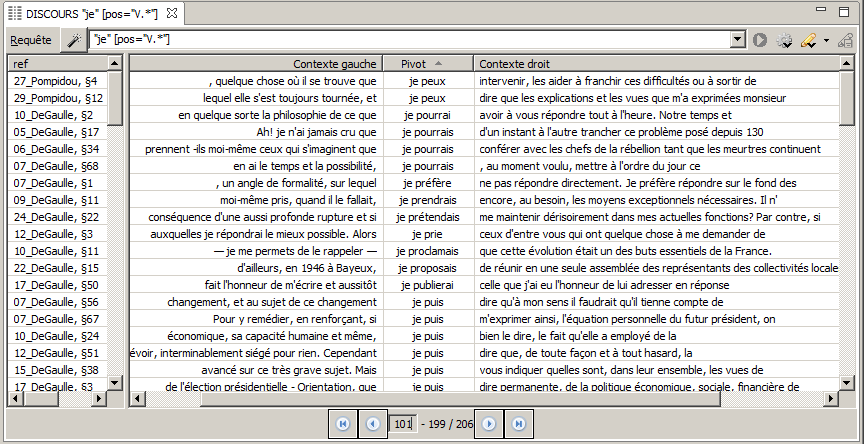
La figure 6.24 montre les résultats :
il y a 206 occurrences ;
les résultats affichés vont du 22ième au 41ième (il s’agit de la deuxième page) ;
la colonne « Pivot » recense les deux mots ciblés par la requête « je » suivi d’un verbe ;
les concordances sont triées par défaut dans l’ordre du texte et du corpus ;
la référence prend ici la forme du nom du locuteur ;
le menu contextuel s’ouvre en cliquant à droite sur une concordance, il permet de :
définir les références : régler les informations affichées dans la colonne référence ;
définir la propriété de tri : définir la propriété de mot utilisée pour l’ordre de tri ;
tri multiple : définir plusieurs clés de tri ;
définir la taille des contextes : choisir le nombre maximum de mots affichés dans les contextes de gauche et de droite ;
lignes par page : définir le nombre de résultats affichés dans une page
définir les propriétés affichées : choisir les propriétés de mots qui seront affichées dans chaque colonne.
La concordance est un tableau que pouvez exporter au format CSV, voir la section 6.15.1.1 Export des tableaux page 125.
7.5.2 Navigation
Une concordance commence par afficher la première page des résultats.
Les boutons de navigation permettent de visionner tous les résultats :
« » : première page ;
«
 » : page précédente ;
» : page précédente ;«
 » : page suivante ;
» : page suivante ;«
 » : dernière page.
» : dernière page.
Le nombre de lignes par page par défaut peut être réglé via le menu « Fichier / Préférences », puis la page « TXM > Utilisateur > Concordances ». Pour un réglage uniquement dans la fenêtre courante de la concordance, il faut passer par le menu contextuel du tableau de la concordance.
7.5.3 Retour au texte
En double-cliquant sur une ligne de la concordance, on retourne à la page de l’édition qui contient le pivot. L’édition est ouverte dans un nouvel éditeur.
Au sein de la page, le pivot est surligné en rouge, tandis que les autres pivots de la concordance se trouvant dans la même page sont surlignés en rouge clair.
Si on re-double-clique sur une ligne de la concordance, le même éditeur est utilisée. Pour une navigation dans l’édition, vous pouvez placer l’éditeur de l’édition à côté de l’éditeur de la concordance.
7.5.4 Tri des concordances
Vous pouvez trier les concordances selon chaque colonne : « Références », « Contexte gauche », « Pivot » et « Contexte droit » en cliquant sur leurs entêtes. Vous pouvez changer l’ordre de classement en cliquant une nouvelle fois sur l’entête. Vous remarquerez qu’alors les clés de tri changent en fonction de l’entête sélectionnée. Le tri par défaut se fait selon le pivot. Toutefois vous avez la possibilité de changer les propriétés de tri en cliquant sur « Options de tri » dans le menu contextuel. Enfin vous pouvez effectuer un tri multiple en changeant chaque clé de tri.
7.5.5 Propriétés de mots et taille de contextes
Chaque colonne contenant une propriété de mot peut être personnalisée soit :
depuis le tableau des réglages de propriétés des paramètres supplémentaires, voir illustration 6.12, organisé horizontalement par colonnes de concordance : la première ligne permet de choisir les propriétés affichées, la deuxième ligne de choisir les propriétés utilisées pour les tris et la troisième de régler la taille des contextes.
depuis la concordance, sélectionner dans le menu contextuel « Options d’affichage ».
7.5.6 Références de concordance
Vous pouvez choisir quelles informations sont affichées dans la colonne « Références ».
Dans le menu contextuel, sélectionner « Options d’affichage des références ». Une fenêtre s’ouvre, comme vous pouvez le constater dans La figure 6.13 :
Toutes les propriétés d’unités de structure et d’unités lexicales se trouvent dans la liste de gauche. Les noms de propriétés contenant le caractère « : » correspondent aux propriétés de structures.
Par exemple, text:loc représente la propriété « loc » de la structure « text », pos représente la propriété « pos » des mots.
Pour choisir une propriété, sélectionnez-là puis cliquez sur le bouton « > » pour la faire glisser dans le champ de droite. La liste qui se formera à droite correspondra à l’affichage dans la colonne référence.
Pour retirer une propriété de l’affichage, sélectionnez-là dans la liste de droite et appuyez sur le bouton « < » afin de la faire re-basculer dans la liste de gauche.
Pour changer l’ordre d’affichage des propriétés dans la référence, on change l’ordre des propriétés dans la liste de droite. Utiliser les boutons monter « ^ » et descendre « v » pour déplacer les propriétés dans la liste.
7.6 Cooccurrences
La commande Cooccurrences calcule le tableau des différents cooccurrents des occurrences d’une requête CQL, trié par défaut par l’indice de spécificité (Lafon, 1980) (un indicateur statistique de présence). Elle permet donc de calculer les cooccurrents d’une forme, d’un lemme, de la succession d’un lemme et d’une catégorie, etc.
L’appel de cette commande ouvre une fenêtre composée d’une zone de paramètres et d’une zone affichant les cooccurrents (Illustration Illustration) :
La zone de paramètres permet de :
Saisir une expression CQL du pivot dans le champ de requête (on peut aussi utiliser l’assistant de requête).
Choisir les propriétés lexicales utilisées pour construire les cooccurrents (forme, lemme, etc.)
Régler les seuils de fréquence, de co-fréquence et d’indice de spécificité pour élaguer les résultats. La co-fréquence est le nombre de rencontres entre le pivot et chaque cooccurrent.
Choisir le type et la taille du contexte de rencontre :
Contexte en structure, si on coche « structure »
Contexte en fenêtre de mots, si on coche « forme »
On peut définir la taille du contexte à gauche et à droite du pivot (attention : en nombre de structures ou en nombre de mots suivant le type de contexte choisi).
On peut ignorer des contextes en décochant « Contexte gauche actif » ou « Contexte droit actif ».
Trier la liste des cooccurrents en cliquant sur l’entête d’une colonne.
Pour lancer le calcul, cliquer sur le bouton  ou appuyer sur « Entrée » après avoir saisi la requête CQL.
ou appuyer sur « Entrée » après avoir saisi la requête CQL.
La liste des cooccurrents est un tableau que vous pouvez exporter au format CSV, voir la section 6.15.1.1 Export des tableaux page 125.
7.7 Progression
Une progression représente graphiquement l’évolution au fil d’un corpus d’un ou de plusieurs motifs, exprimés par des requêtes CQL. Elle produit un graphique cumulatif ou un graphique de densité et superpose à la demande des positions de structures du corpus. La zone des paramètres principaux permet d’ajouter des requêtes au graphique de progression. La zone des paramètres complémentaires :
On peut d’abord préciser le type de graphique: cumulatif ou en densité
On peut ensuite choisir une unité structurelle dont on veut visualiser les limites dans le graphique. Les limites seront choisies à partir des valeurs d’une des propriétés de la structure : chaque limite de l’unité, correspondant à une valeur de la propriété, sera représentée sur le graphique sous la forme d’une barre verticale.
- On peut filtrer les valeurs de la propriété au moyen d’une expression régulière pour n’afficher une barre de délimitation que pour les valeurs correspondant à cette expression
Enfin, on saisit les requêtes CQL des motifs à visualiser (éventuellement avec l’aide de l’assistant). On peut supprimer une requête avec le bouton « supprimer » (icone de croix)
- On peut charger un ensemble de requêtes (nommées) à partir d’un fichier au format « .properties » : chaque ligne à la forme « nom=requête».
Exemple de fichier « .properties » :
verbes=[frpos=“V.+”]
adverbes=[frpos=“ADV”]
adjectifs=[frpos=“ADJ”]
…
pronoms=[frpos=“PRO”]
Si le mode « densité » est sélectionné, on peut faire varier la fenêtre de densité par un facteur multiplicatif. Par défaut, la taille de la fenêtre, est la distance minimale entre chaque unité de structure (entre chaque texte si la structure sélectionnée est « text »).
Des options d’affichage sont disponibles :
Afficher le graphique en noir & blanc
Répéter ou pas les valeurs de propriétés de structure.
Utiliser des styles de ligne différents
En cliquant sur « OK » on obtient le graphique de progression tel que dans La figure 6.16. Dans ce graphique, les dates sont affichées en début de discours. Les courbes représentent les progressions respectives des mots « France » et « Algérie », à chaque marche, ou point, d’une courbe correspond une occurrence de mot.
Le graphique est exportable sous forme d’image, voir la section 6.15.1.2 Export des graphiques page 126.
7.7.1 Sélection de points dans les courbes de progression
Comme pour les autres graphiques, il est possible de mettre en évidence des points des courbes en utilisant le mécanisme de sélection par la souris :
Clic gauche : sélection du point (dé-sélection des points déjà sélectionnés)
Ctrl-clic gauche (Cmd-clic gauche sous Mac) : ajout du point à la sélection (ou retrait)
Màj-clic gauche : ajout de tous les points entre le point et celui déjà sélectionné à la sélection (ou retrait)
La sélection de point peut être déplacée le long de la courbe avec les touches raccourcis « flèche gauche » et « flèche droite ».
Cette mise en évidence est exportée avec le graphique lorsque l’on exporte la vue depuis la barre d’outils.
7.7.2 Appels hypertextuels depuis les courbes de progression
Il est possible de lancer deux commandes à partir d’une courbe de progression par lien hypertextuel :
double clic gauche sur un point : ouvre la concordance des occurrences (points) de la progression et la positionne sur la ligne correspondant au point cliqué. Le déplacement de la sélection de point dans la courbe est synchronisé avec l’affichage de la ligne correspondante dans la concordance. Cet outil permet de lire rapidement les contextes d’emploi des occurrences correspondant à certains points d’une progression, par exemple au début où la la fin de changements de rythme dans une courbe ou dans des zones de forte densité (pente forte dans la visualisation cumulative) ;
- il est possible d’ouvrir par lien hypertextuel plusieurs concordances simultanément depuis des courbes pour pouvoir comparer leur contexte en même temps ;
Ctrl-double clic gauche (Cmd-double clic gauche sous Mac) : lance le retour au texte de l’occurrence correspondant au point cliqué. L’édition est positionnée sur l’occurrence sélectionnée, qui est mise en évidence. Le déplacement de la sélection de point dans la courbe est synchronisé avec la mise en évidence dans l’édition. Cet outil permet de lire rapidement les contextes d’emploi les plus larges des occurrences correspondant à certains points d’une progression.
7.8 Références
La commande Références affiche la liste toutes les références des valeurs retournées par une requête CQL à partir des informations des unités structurelles les contenant.
A côté de chaque référence, on trouve, entre parenthèses, la fréquence de la référence. C’est à dire le nombre de fois qu’un pivot à cette référence. Les références peuvent être triées par fréquence ou alphabétiquement.
Si la requête CQL correspond à une succession d’unités lexicales, c’est alors la première unité qui est prise en compte.
Utilisation :
On doit saisir une requête CQL dans le champ requête
On choisit la propriété d’affichage des occurrences, et ainsi la façon de les regrouper
On peut choisir les propriétés de structures à utiliser. Tout comme la commande concordance, il s’agit d’un patron.
Enfin, on lance le calcul à l’aide du bouton ,
7.9 Sous-corpus
Cette commande construit un sous-corpus du corpus sélectionné. Le sous-corpus est représenté comme un descendant du corpus dans la vue « Corpus ».
Cette commande ouvre une boîte de dialogue de nom « Créer un sous-corpus ». Elle est composée de trois onglets : ils permettent de construire des sous-corpus en mode simple, en mode assisté ou en mode avancé.
7.9.1 Construire un sous-corpus : mode « simple »
La figure 6.18 affiche la boîte de dialogue du mode simple de la commande « Construire un sous-corpus ».
Ici, on doit :
OPTIONNEL : entrer le nom du nouveau corpus : il sera affiché dans la vue « corpus »
sélectionner une unité structurelle
sélectionner la propriété de cette unité.
sélectionner une ou plusieurs valeurs
Le nouveau corpus contiendra toutes les unités lexicales se trouvant dans les unités structurelles ainsi désignées.
7.9.2 Construire un sous-corpus : mode « assisté »
La figure 6.19 présente le formulaire de création de sous-corpus en mode « assisté ». qui permet de formuler la requête de création de sous-corpus à partir de différentes propriétés d’une structure
Dans cette fenêtre, on doit :
OPTIONNEL : Saisir le nom du sous-corpus
Cocher « tous les critères » pour considérer tous les critères de recherche saisis ou cocher « certains critères » pour ne considérer que certains d’entre eux.
Sélectionner la structure du sous-corpus qui sera utilisée
Saisir des critères de sélection :
ajouter un critère avec le bouton « + »
supprimer un critère avec le bouton « - »
choisir la propriété utilisée par le critère :
- qui contient ou qui ne contient pas l’attribut sélectionné
Rafraîchir la requête de création du sous-corpus
Modifier si besoin la requête
Cliquer sur « OK » pour créer le sous-corpus
Attention, rajouter un critère de sélection rajoute une contrainte logique de type « ET ». Vous pouvez remplacer les « & » de la requête par des « | » si vous voulez « ajouter ».
7.9.3 Construire un sous-corpus : mode « avancé »
La figure 6.20 présente la boîte de dialogue du mode avancé[50] qui permet à une utilisateur expert de construire des sous-corpus à l’aide du langage de requête CQL.
Ici on doit :
OPTIONNEL : entrer le nom du nouveau corpus qui apparaîtra dans la vue corpus
écrire une requête CQL qui sélectionnera les unités lexicales du nouveau sous-corpus
Le sous-corpus contiendra toutes les unités lexicales sélectionnées par la requête.
7.10 Partition
Cette commande construit une partition du corpus sélectionné. La nouvelle partition apparaît comme un descendant dans la vue « Corpus ».
Cette commande ouvre une boîte de dialogue intitulée « Créer une partition ». Elle est composée de trois onglets : mode simple, assisté et avancé.
7.10.1 Construire une partition : mode « simple »
La figure 6.21 montre la fenêtre du mode simple.
Ici on doit :
OPTIONNEL : entrer le nom de la nouvelle partition qui apparaîtra dans la vue « corpus »
sélectionner une unité structurelle
sélectionner la propriété de l’unité structurelle sélectionnée.
Les parties de la nouvelle partition seront construites, en tant que sous-corpus, en fonction des différentes valeurs de l’unité structurelle sélectionnée. On ne peut pas accéder aux parties individuellement mais elles sont accessibles via l’objet partition et les commandes qui permettent de mettre ces parties en contraste : Spécificités et AFC.
7.10.2 Construire une partition : mode « assisté »
Le mode assisté permet de définir plus finement les parties de la partition en offrant la possibilité de sélectionner les différentes valeurs de la propriété de structure à utiliser pour composer chaque partie.
La figure 6.22 présente la fenêtre de création de partition en mode assisté.
Ici, il faut :
OPTIONNEL : entrer le nom de la partition qui apparaîtra dans la vue « corpus »
sélectionner une unité de structure, ainsi qu’une de ses propriétés
sélectionner les valeurs qui constitueront une partie de la partition
cliquer sur « nouvelle partie » pour créer une partie supplémentaire
entrer le titre de la partie dans le champ correspondant
cliquer sur « affecter » afin de basculer les valeurs précédemment sélectionnées dans cette partie
on peut cliquer sur « supprimer » afin d’enlever certaines valeurs à cette partie
on peut cliquer sur la croix pour supprimer la partie
on peut cliquer sur « Supp. toutes les parties » afin de supprimer en une seule fois toutes les parties d’un coup
cliquer sur « OK » crée la partition ainsi paramétrée.
7.10.3 Construire une partition : mode « avancé »
La figure 6.23 présente la fenêtre de création de partition en mode avancé[51].
Ici on doit :
OPTIONNEL : entrer le nom du nouveau corpus qui apparaîtra dans la vue « corpus »
écrire autant de requêtes CQL qui sélectionnent chacune les unités lexicales qui composent chaque partie
utiliser le bouton ‘+’ pour ajouter une nouvelle partie et saisir la requête correspondante
utiliser le bouton ‘-’ pour supprimer une partie
La nouvelle partition sera composée de toutes les parties définies, chacune contenant les unités lexicales sélectionnées par la requête correspondante.
Attention, la bonne couverture du corpus total par l’union des différentes parties est de la responsabilité de l’utilisateur.
Les parties de partitions avancées sont nommable en cliquant sur leur nom.
7.11 Table lexicale
Une table lexicale réunit dans un tableau les fréquences des différentes unités lexicales d’une partition ou d’un index de partition. Elle permet de construire toutes les variantes nécessaires du « tableau lexical entier » (TLE) de la textométrie.
Construite à partir d’une partition, il faut d’abord choisir la propriété de mot à partir de laquelle les fréquences seront construites à l’aide du menu « Propriété » de la barre d’outils, comme ce qui apparaît dans la figure 6.2.
À partir d’un index de partition, les unités et les fréquences sont prises directement dans l’index.
Enfin, une table lexicale est créée automatiquement par les commandes AFC, Classification et Spécificités appliquées à une partition. Cette table lexicale est masquée dans la vue Corpus par défaut.
Le tableau se présente de la façon suivante : une unité par ligne, une partie par colonne.
Il est éditable : les lignes et les colonnes peuvent être fusionnées ou supprimées, il est possible de filtrer certaines lignes en fonction de leur fréquence, la taille du tableau peut également être limitée par un nombre de lignes maximum.
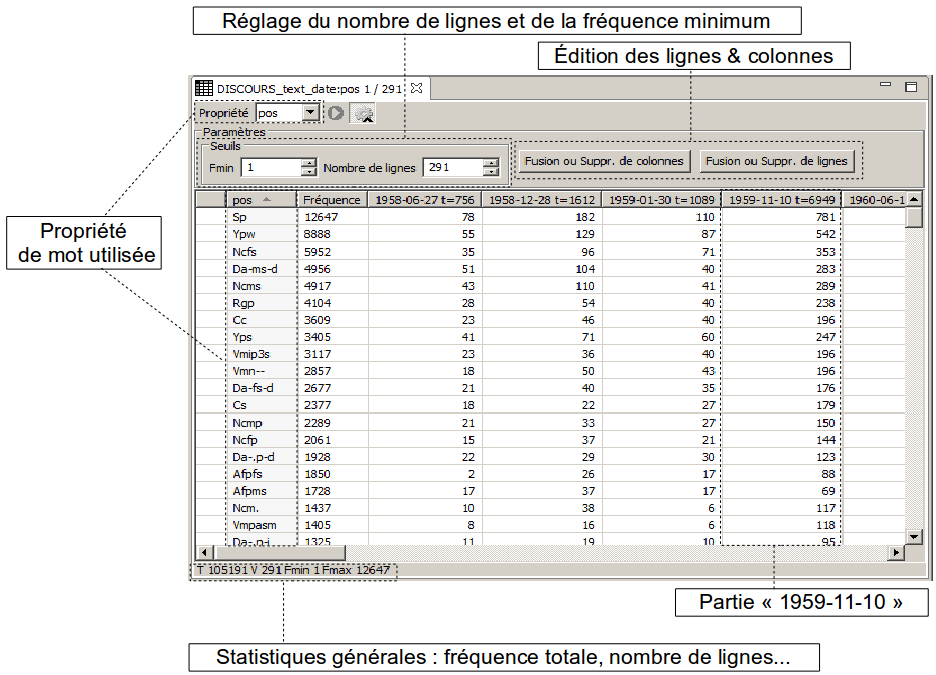
Dans la figure ci-dessus on peut voir la table lexicale formée à partir de la partition Date du corpus DISCOURS. Il est possible de :
Régler le nombre de ligne ainsi que la fréquence minimum. Il faut valider le choix en cliquant sur le bouton « Garder »
Fusionner ou supprimer des colonnes : en cliquant sur le bouton « Fusion ou Suppr. de colonnes ». Ceci ouvre une boîte de dialogue (voir illustration 6.25) :
dans cette fenêtre on commence par sélectionner dans la liste de gauche la ou les colonnes à manipuler : soit en sélectionnant directement les noms avec la souris, soit via le champ de recherche situé en haut à gauche (qui sélectionne les noms après avoir saisi une expression régulière et cliqué sur le bouton « chercher » - loupe).
puis on bascule les noms sélectionnés dans la liste de droite (des colonnes qui seront manipulées) avec le bouton « > »
le bouton « < » sert à re-basculer des noms de colonnes dans la liste de gauche
on coche ensuite « fusionner » ou « supprimer » en fonction de l’opération souhaitée. Dans le cas d’une fusion, il faut préciser le nom de la nouvelle colonne résultat ;
Enfin, on clique sur « OK » pour procéder à l’opération.
Fusionner ou supprimer des lignes : en cliquant sur le bouton « Fusion ou Suppr. de lignes » : une fenêtre similaire à celle des colonnes permet d’éditer les lignes du tableau.
On peut trier les colonnes en cliquant sur leurs en-têtes ;
Enfin, il est possible d’exporter la table obtenue par le biais du menu contextuel.
7.11.1 Sauvegarde d’une table lexicale
Les modifications de tables lexicales sont perdues quand vous quittez TXM. Si vous souhaitez conserver une table lexicale pour la réutiliser au-delà de la session de travail courante, le principe est de la conserver dans un fichier en l’exportant, puis de la récupérer dans une nouvelle session de TXM en l’important depuis ce fichier.
7.11.1.1 Exporter une table lexicale
Utiliser la commande « Exporter > Données… ». Le fichier créé est au format CSV et a pour extension « .csv ». Les caractéristiques du CSV, comme le caractère séparateur de colonnes, etc., peuvent être réglées dans la page de préférences « TXM > Utilisateur > Export ». Il faut pas la suite veiller à ne pas modifier le format du fichier pour pouvoir réimporter la table dans TXM.
7.11.1.2 Importer une table lexicale
Commencer par créer une table lexicale quelconque dans le corpus de
travail. Puis lancer la commande « Importer une table lexicale depuis un
fichier… ». Indiquer alors le fichier contenant la table que vous
aviez exportée : celle-ci va remplacer le contenu de la table
courante.
Remarque : les nouvelles modifications que vous effectuez dans la table
avec TXM ne sont pas enregistrées dans le fichier depuis lequel vous
avez importé la table. Si vous souhaitez enregistrer les modifications
faites lors de la session il vous faut faire un nouvel export de la
table.
7.12 Spécificités
La commande Spécificités calcule un indice rendant compte de l’étonnement que l’on peut avoir du nombre si important (ou si faible) d’occurrences d’un mot ou d’une requête CQL dans une colonne de table table lexicale, une partie de partition ou, de façon générale, dans un sous-corpus par rapport au corpus entier, étant donnés les quatre paramètres suivants :
f : le nombre d’occurrences dans le sous-corpus ;
F : le nombre d’occurrences dans le corpus entier ;
t : le nombre de mots du sous-corpus ;
T : le nombre de mots du corpus entier.
7.12.1 Indice de spécificité
Afin de calculer la probabilité d’apparition d’un événement textuel dans une partie d’un corpus plutôt qu’une autre, un événement étant défini comme l’apparition d’un mot ou d’une expression CQL quelconque, on peut progressivement estimer le nombre d’apparitions le plus vraisemblable de la manière suivante :
le décompte des occurrences de l’expression CQL (ou d’une forme graphique simple) dans chaque partie, soit la fréquence, permet de se faire une première idée contrastive entre les parties.
diviser cette fréquence par le nombre total d’occurrences se trouvant dans la partie considérée (ou dira aussi la taille de la partie) permet d’utiliser les « fréquences relatives ». On a alors « normalisé » la fréquence ou encore on l’a pondérée indépendamment de la taille de chaque partie. Ce qui permet de comparer plus sereinement les fréquences entre elles.
on peut faire plus précis que cela encore : c’est l’objet du calcul de la mesure de spécificité d’une apparition dans une partie mise en œuvre dans TXM. En effet, normaliser en divisant par la taille de la partie nous fait considérer implicitement (ou non) que les fréquences relatives sont représentatives des fréquences d’origine (avant la division par la taille). Pour ce faire, en se trompant le moins possible en dehors de toute information complémentaire, on peut considérer la fréquence relative comme étant le maximum de vraisemblance du nombre d’apparition dans une partie de taille quelconque selon une loi d’apparition normale. On considère en quelque sorte que la fréquence relative se comporte comme le mode d’une distribution de probabilité normale (le milieu de la cloche de Gauss, là où c’est le plus élevé et donc le plus probable), soit la moyenne (cf. propriétés de la loi normale : moyenne, écart-type…). Or, il se trouve que la probabilité d’apparition d’une forme graphique - ou de façon plus générale d’une expression CQL - dans une partie n’a aucune raison de se comporter selon une loi normale. C’est-à-dire dont la distribution ressemble à une belle cloche de Gauss, avec une moyenne, un écart-type, etc. C’est ce qu’a fait remarquer Pierre Lafon dans sa thèse (Lafon, 1984), en insistant sur la déformation de la distribution pour les petites fréquences (≪20 par exemple) qui ne ressemble pas du tout à une cloche de Gauss. Il a formalisé cette apparition et constaté qu’elle était plutôt du type hypergéométrique. Cette loi de probabilité est très générale et apparaît sous diverses formes. Mais le plus souvent dans le cas qui nous préoccupe, elle ressemble à une cloche de Gauss dissymétrique vers la droite avec une queue s’affaissant petit à petit vers les hautes fréquences. Et le mode de cette distribution, c’est à dire le maximum de vraisemblance d’apparition que nous cherchons à estimer ne s’obtient pas par une moyenne arithmétique mais plutôt par l’équation 6.26.
Dans TXM, le calcul de la probabilité qu’une forme A apparaisse f fois dans une partie p de longueur t, la forme apparaissant F fois en tout dans l’ensemble du corpus dont la longueur totale est de T occurrences, a été modélisé par Pierre Lafon (Lafon, 1980) et peut s’exprimer formellement par l’équation 6.27 [52].
Le calcul exact de l’indice de spécificité utilisée dans TXM est celui du calcul de la probabilité du fait que l’événement apparaisse autant de fois qu’on l’observe effectivement dans la partie (soit \(f_{\text{obs}}\)) ou plus fréquemment encore à concurrence de la taille de la partie (en suivant la loi hypergéométrique décrite par l’équation 6.27 qui dépend de f, t, F et T). Concrètement, on obtient cette mesure en sommant les valeurs de la probabilité \(\text{Prob}_{spécif}\) pour chaque fréquence d’apparition possible comme le montre l’équation 6.28 .
7.12.2 Présentation des résultats
Dans TXM, la spécificité est représentée par la partie entière des logarithmes en base 10 (log10) des estimations de probabilité de spécificité car, comme le nom hypergéométrique le suggère, les probabilités obtenues par les calculs varient dans un domaine exponentiel et l’ordre de grandeur de la probabilité suffit en général à la comparer aux autres. On compare donc des ordres de grandeur plutôt que les probabilités elles-mêmes.
Par convention, la représentation de la sous spécificité (ou sous-représentation) se distingue de celle de la sur spécificité (ou sur-représentation) par un signe moins (-) situé devant l’indice. On s’intéressera alors aux probabilités faibles, donc aux valeurs de log10 et d’indice importantes, qui rendent compte :
soit d’un nombre d’apparitions plus faible que prévu (avec un préfixe « - ») si l’observation est inférieure au mode de la distribution théorique (c’est-à-dire si le nombre d’apparitions de l’événement dans la partie est inférieur au maximum de vraisemblance estimé par notre modélisation hypergéométrique de la distribution (cf. l’équation 6.26). On parlera alors de sous-spécificité ou spécificité négative ;
soit d’un nombre d’apparition plus important que prévu (sans préfixe « - ») si l’observation est supérieure au mode de la distribution théorique. On parlera alors de sur-spécificité ou spécificité positive.
Ces grandes valeurs d’indice (positives ou négatives) s’opposent aux fortes probabilités (par exemple supérieures à 5% de chance), donc aux valeurs de log10 faibles, qui indiqueront plutôt la banalité de l’apparition dans la partie (car prévisibles d’après le modèle des spécificités).
Pour les personnes intéressées par la valeur exacte de la probabilité calculée plutôt qu’au classement des événements entre eux par le biais de l’ordre de grandeur de cette probabilité (qui est, notre usage principal des estimations de probabilité), la macro PlotSpecif présentée à la section suivante permet non seulement de réaliser directement le calcul de l’indice de spécificité en fonction des paramètres du modèle mais surtout de situer cette valeur dans la courbe de densité de probabilité.
7.12.3 Calcul direct et visualisation de l’indice de spécificité
La macro « PlotSpecif » permet de visualiser la courbe de la densité de probabilité de spécificité pour des valeurs de paramètres F, t et T choisis par l’utilisateur, et la position par rapport à la courbe de la fréquence observée (f).
Pour utiliser cette macro :
ouvrir la vue « Vues / Macro » ;
dans la vue, ouvrir la section « r » ;
double-cliquer sur la macro « PlotSpecif » pour la lancer :
la fenêtre de saisie des paramètres s’ouvre (ill. 6.29). Les paramètres par défaut sont ceux de l’exemple du mot « peuple » prononcé dans le discours D9 de Robespierre illustré dans (Lafon,
- (voir la Figure 1, pp 140-141) :
f la fréquence de la forme dans la partie ;
F la fréquence totale de la forme dans le corpus ;
t le nombre total d’occurrences de la partie ;
T le nombre total d’occurrences du corpus.
cliquer ensuite sur « Exécution » pour afficher la courbe de la densité de probabilité pour ces paramètres (ill. 6.30) :
avec les paramètres par défaut, le nombre d’apparitions le plus probable (le mode) est de 5 ;
la probabilité d’apparaître exactement 11 fois dans le discours D9 est de 0,01013 % ;
la probabilité d’apparaître 11 fois et plus dans le discours D9 (pour le calcul de l’indice de spécificité) est de 0,01699 %
Pour reproduire la forme de la distribution correspondant à un cas précis se trouvant dans un tableau de résultats de spécificités, il suffit donc de lancer la macro PlotSpecif avec les paramètres f, F, t et T observés dans le tableau.
7.12.4 Application du calcul des spécificités
Les spécificités peuvent s’appliquer à :
une partition ;
une table lexicale ;
ou un sous-corpus.
7.12.4.1 Spécificités d’une partition
La commande Spécificités appliquée à une partition ouvre le fenêtre de résultat suivante :
dans laquelle on commence par sélectionner la propriété de mot qui fait l’objet du calcul (champ « Propriété »).
Après le lancement du calcul avec le bouton  ,
les résultats sont présentés sous forme d’un tableau (voir l’exemple
figure 6.32) :
,
les résultats sont présentés sous forme d’un tableau (voir l’exemple
figure 6.32) :
lignes : les différentes « unités » ou valeurs de la propriété de mot considérée (par exemple les différentes formes de mots pour la propriété « word ») ;
colonnes :
la première colonne contient les différentes valeurs de la propriété (par exemple la forme « nous ») ;
la deuxième colonne contient la fréquence totale ‘F’ de cette valeur dans tout le corpus (par exemple 694 « nous » dans le corpus). Dans le titre de la colonne, ‘T’ représente le nombre total d’occurrences du corpus (par exemple une taille totale de 100 810 mots) ;
les autres colonnes fonctionnent par paire :
une première colonne contient la fréquence de la valeur dans la partie (par exemple 6 occurrences de « nous » dans la partie « Allocution radiotélévisée »). Dans le titre de cette colonne, ‘t’ représente la taille de la partie ;
la seconde contient l’indice de spécificité de la valeur pour la partie (par exemple 21,3 de spécificité pour « nous » dans la partie).
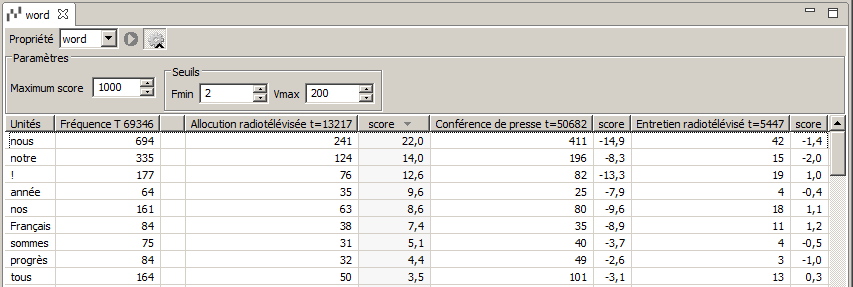
La figure 6.32 présente les résultats de la commande Spécificités portant sur la forme graphique de tous les mots de la partition sur le type de discours du corpus DISCOURS. La tableau est trié dans l’ordre décroissant de la colonne d’indice de spécificité de la partie « Allocution radiotélévisée ». On peut y lire que les formes les plus spécifiques du discours de type « Allocution radiotélévisée » sont :
« nous » ayant un indice de spécificité de 21,3 pour 241 apparitions dans ce genre sur un total de 694 apparitions dans le corpus ;
« notre » ayant un indice de spécificité de 13,6 pour 124 apparitions dans ce genre sur un total de 335 apparitions ;
etc.
Vous pouvez exporter ce tableau au format CSV, voir la section 6.15.1.1 Export des tableaux page 125.
7.12.4.1.1 Tri des résultats
On trie le tableau selon les différentes colonnes pour les interpréter en cliquant sur leur entête. Cliquer une seconde fois inverse l’ordre de tri.
Trier une colonne d’indice de façon décroissante, permet d’accéder rapidement aux mots plus présents que prévu par rapport à l’ensemble du corpus. Les derniers mots de la liste sont moins présents que prévu et les mots intermédiaires – autour de l’indice 0 – sont considérés comme banals (on n’est pas étonné de leur fréquence dans la partie).
7.12.4.1.2 Visualisation graphique des indices de spécificité
Les indices de spécificité peuvent être visualisés sous forme graphique. On sélectionne dans le tableau au moyen de la souris[53] les lignes pour lesquelles on souhaite une visualisation puis on lance la commande « Calculer le diagramme en bâtons des lignes sélectionnées » via le menu contextuel. Cela produit un graphique comme illustré ci-dessous :
Dans le graphique :
chaque partie est représentée par un groupe de barres multicolores contiguës, placées dans le même ordre que dans le tableau ;
la spécificité de chaque valeur de propriété de mot (lemme du mot dans cet exemple) sera représentée par une barre de la même couleur dans chaque partie ;
les couleurs sont légendées dans le coin inférieur droit du graphique ;
deux lignes rouges horizontales délimitent la bande de banalité autour de l’axe d’indice 0 (les barres qui n’en sortent pas sont considérées comme banales).
La position de la bande de banalité est modifiable dans la zone des paramètres étendus de la commande.
Le graphique est exportable sous forme d’image, voir la section 6.15.1.2 Export des graphiques page 126.
7.12.4.2 Spécificités d’une table lexicale
On peut appliquer le calcul des spécificités à une table lexicale.
Issue d’une partition, la table lexicale permet d’affiner le tableau de données avant le calcul des spécificités, typiquement par fusion ou suppression de lignes.
Dans ce contexte, la propriété de mot à considérer a déjà été choisie et le calcul des spécificités se lance directement.
Les résultats se présentent comme pour les spécificités d’une partition.
7.12.4.3 Spécificités d’un sous-corpus
On peut appliquer le calcul des spécificités à un sous-corpus, comme si on limitait le calcul à une seule partie d’une partition.
La commande Spécificités sur un sous-corpus permet de choisir la propriété de mot sur laquelle seront appliqués les calculs, puis de lancer le calcul :
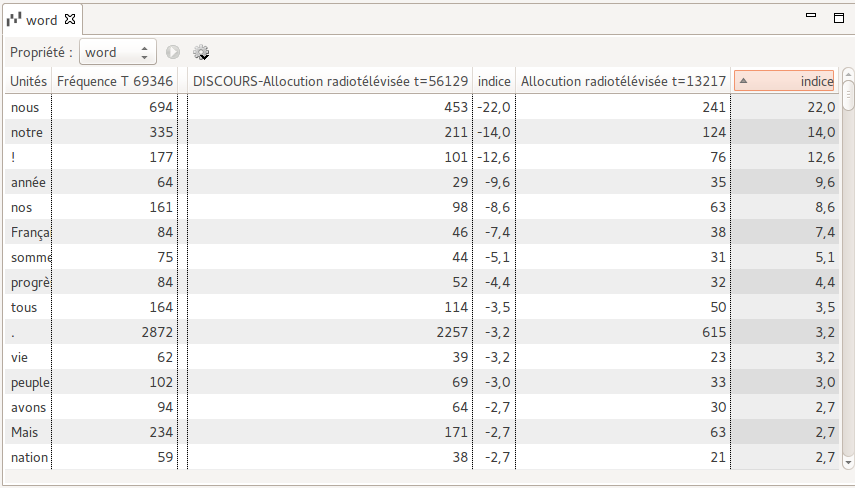
Les résultats sont présentés sous forme de tableau
lignes : les différentes valeurs de la propriété de mot considérée (par exemple les différentes formes de mots) ;
colonnes :
groupe principal :
la première colonne affiche la valeur de la propriété correspondant à la ligne (par exemple la forme « nous ») ;
la deuxième colonne affiche la fréquence totale ‘F’ de cette valeur dans tout le corpus (par exemple 694 « nous » dans le corpus). Dans le titre de la colonne, ‘T’ représente le nombre total d’occurrences du corpus (par exemple une taille totale de 69 346 mots) ;
groupe du complémentaire du sous-corpus :
la troisième colonne affiche la fréquence de la valeur dans le complémentaire du sous-corpus (par exemple 453 occurrences de « nous »). Dans le titre de cette colonne qui mentionne le « nom du corpus - le nom du sous-corpus », ‘t’ représente la taille du complémentaire ;
la quatrième colonne affiche l’indice de spécificité de la valeur pour le complémentaire (par exemple spécificité de
- 22 pour « nous » dans le complémentaire);
groupe du sous-corpus :
la cinquième colonne affiche la fréquence de la valeur dans le sous-corpus (par exemple 241 occurrences de « nous »). Dans le titre de cette colonne qui mentionne le nom du sous-corpus, ‘t’ représente la taille de la partie ;
la sixième colonne affiche l’indice de spécificité de la valeur pour la partie (par exemple spécificité de 22 pour « nous » dans le sous-corpus) .
7.13 Analyse Factorielle des Correspondances (AFC)
La commande AFC 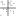 calcule l’analyse factorielle
des correspondances (Benzécri, 1979b) d’une table lexicale ou d’une
partition.
calcule l’analyse factorielle
des correspondances (Benzécri, 1979b) d’une table lexicale ou d’une
partition.
Quand l’AFC est appliquée à une partition, une table lexicale est calculée à la volée puis l’AFC est appliquée à cette table lexicale. Celle-ci est masquée par défaut dans la vue Corpus. La fenêtre de résultat de l’AFC permet alors de régler les paramètres suivants :
Propriété : le nom de la propriété de mot à utiliser pour construire les vecteurs de fréquences (word, *lemma, *pos…) ;
Vmax : le nombre maximum de lignes de la table ;
Fmin : la fréquence totale minimale d’une valeur de propriété pour faire partie de la table.
Dans la table lexicale calculée à la volée, les colonnes correspondent aux parties de la partition et contiennent le vecteur colonne des fréquences des valeurs de la propriété de mot choisie. Chaque ligne contient la fréquence au sein de chaque partie d’une des valeurs de la propriété de mot.
Cette commande doit être appliquée à une partition constituée d’au moins quatre parties ou à une table lexicale constituée d’au moins quatre colonnes.
Les résultats sont affichés dans deux vues côte-à-côte :
la vue de gauche affiche une représentation graphique des plans factoriels
la vue de droite affiche le détail des résultats sous la forme de tableaux. Elle se subdivise en quatre onglets :
les valeurs propres
les informations sur les lignes
les informations sur les colonnes
l’histogramme des valeurs propres
La fenêtre de visualisation des plans factoriels permet de choisir :
quel plan est visualisé : choisir dans le menu « Axes : » les axes du plan à visualiser ;
quels éléments sont affichés dans le graphique : cliquez sur les boutons « Afficher les colonnes » ou « Afficher les lignes » de la barre d’outils des graphiques selon les points que vous souhaitez visualiser, ensemble ou séparément.
Par défaut, l’AFC affiche seulement les colonnes dans le plan factoriel. Ce paramètre peut être modifié dans les préférences de l’AFC, dans la section « Rendu des graphiques » :
« Afficher les lignes » : affiche les valeurs de propriétés de mot ;
« Afficher les colonnes » : affiche les parties.
d’afficher ou non un point en plus du label avec la commande « Afficher/masquer le tracé des points »
L’échelle du graphique peut être modifiée avec la molette de la souris et sa position avec le bouton gauche de la souris.
L’échelle et la position du graphique peuvent être réinitialisées en cliquant sur le bouton « Rétablir la vue initiale ».
Voir également les raccourcis graphique de zoom, déplacement etc. dans la section 6.14.
Dans le volet de droite, diverses informations sont disponibles afin d’aider l’utilisateur à interpréter les coordonnées des colonnes (variables) ou des lignes (individus).
Le tableau des valeurs propres indique leur rang, leur valeur, leur pourcentage d’inertie ainsi que le cumul des pourcentages.
Le graphe en barres des valeurs propres en donne un aperçu analogique.
Les tableaux d’information sur les colonnes et les lignes indiquent :
la qualité des plans « Q- »: la représentation du point dans chaque plan, calculée comme la somme des cos² du point sur les deux axes concernés : plus la qualité est proche de 1, moins la position du point est déformée par la projection dans le plan.
le poids relatif « Mass »: la fréquence est rapportée à la somme des fréquences des autres mots (lignes).
le carré de la distance du point à l’origine « Dist » (l’origine est le centre de gravité du nuage de points : plus la distance est grande, plus le point s’écarte du profil moyen, autrement dit plus il est original par rapport au reste du corpus)
la participation du point à la construction de l’axe « Cont- ». La somme des contributions vaut 100 et les points qui présentent les plus fortes contributions pour un axe donné servent à interpréter l’axe.
le cos² du point sur chaque axe « Cos² »: la mesure de l’angle entre le vecteur représentatif du point et l’axe. Un cos² proche de 1 indique que le point est bien représenté sur l’axe alors qu’un cos² proche de 0 indique que la projection déforme fortement le point par rapport à cet axe et qu’il vaut mieux donc éviter d’interpréter la position du point par rapport aux autres selon la coordonnée sur cet axe. En particulier, un point qui a un cos² faible sur les deux axes de la représentation choisie a une position trompeuse ; sa proximité apparente avec d’autres points ne doit pas être interprétée dans ce plan.
les coordonnées des points dans l’espace des trois premiers axes « c- ».
Les fenêtres de résultats offrent un mécanisme de sélection multiple et de mise en évidence des points combiné entre les points des graphiques et les lignes des tableaux de données. Cliquer sur un point dans le graphique ou dans l’un des tableaux a pour effet de le mettre en surbrillance. La sélection multiple se fait par le mécanisme habituel du système d’exploitation : Ctrl-Clic gauche (Windows et Linux) et Cmd-Clic gauche (Mac OS X) permute entre l’ajout et le retrait d’un point dans la sélection en cours.
La commande de recherche par expression régulière dans un tableau de données (raccourcis Ctrl-F) peut être utilisée conjointement avec la mise en évidence par sélection multiple et étendue (voir également la section dédiée à la sélection multiple et étendue : « 6.14 Visualisations graphiques » page 124).
Les tableaux de données de l’AFC peuvent être exportés au format TXT avec la commande « Fichier > Exporter > Données… ».
Le plan factoriel courant est exportable sous forme d’image, voir la section 6.15.1.2 Export des graphiques page 126.
L’algorithme de la commande AFC est implémenté par le package FactoMineR (Lê, Josse, & Husson, 2008).
Pour de plus amples informations, notamment d’un point de vue R, merci de consulter la documentation de ce package :
documentation R officielle :
http://cran.r-project.org/web/packages/FactoMineR/index.htmlmanuel PDF :
http://cran.r-project.org/web/packages/FactoMineR/FactoMineR.pdfsite web de référence : http://factominer.free.fr
documentation de référence (dont monographies) : http://factominer.free.fr/docs/index.html
7.14 Classification Ascendante Hiérarchique (CAH)
La commande Classification calcule la classification ascendante hiérarchique (CAH) (Benzécri, 1979a) des colonnes ou des lignes d’une table lexicale ou d’une partition.
Quand elle est appliquée à une partition, une table lexicale est d’abord construite à la volée puis la CAH est appliquée à cette table lexicale. Cette table lexicale est masquée par défaut.
Dans la table lexicale calculée à la volée, les colonnes correspondent aux parties et contiennent le vecteur colonne des fréquences des valeurs de la propriété de mot choisie, et les lignes contiennent les fréquences au sein de chaque partie d’une des valeurs de la propriété de mot.
La commande CAH doit être appliquée à une partition constituée d’au moins quatre parties ou à une table lexicale constituée d’au moins quatre colonnes.
La commande CAH s’appuie également sur une AFC calculée à la volée à partir de la table lexicale. Cette AFC est masquée par défaut.
Les paramètres suivants sont directement modifiables dans la fenêtre de résultat de la CAH :
Propriété : le nom de la propriété de mot à utiliser pour construire les vecteurs de fréquences (word, *lemma, *pos…) ;
Vmax : le nombre maximum de lignes de la table ;
Fmin : la fréquence totale minimale d’une valeur de propriété pour faire partie de la table.
La barre d’outils de la fenêtre de résultats permet de :
choisir le nombre de classes à représenter (colorier) dans le dendrogramme (menu « Nombre de classes : ») ;
choisir la dimension de la classification (colonnes ou lignes) avec les boutons et .
La visualisation des résultats en 2D affiche :
au centre le dendrogramme des regroupements par classes d’éléments, composé :
de cadres de couleur correspondants aux regroupements par classes ;
de l’échelle des indices de niveaux de regroupement située à gauche ;
en haut à droite le diagramme des indices de niveaux (du nœud le plus haut au nœud le plus bas du dendrogramme).
On trouvera des paramètres complémentaires dans les préférences de la classification :
la méthode d’agrégation à utiliser (ward , average…) ;
la distance à utiliser (euclidienne, manhattan) ;
le type de visualisation graphique du dendrogramme : 2D ou 3D ;
le nombre de classes à représenter par défaut.
La visualisation graphique en 3D combine la visualisation du dendrogramme des classes avec celle des positions des dimensions à classer (colonnes ou lignes) dans le premier plan factoriel de l’AFC correspondante.
Les tableaux de données de la CAH peuvent être exportés au format TXT avec la commande « Fichier > Exporter > Données… ».
Le dendrogramme est exportable sous forme d’image, voir la section 6.15.1.2 Export des graphiques page 126.
L’algorithme de la commande CAH est implémenté par le package FactoMineR (Lê et al., 2008).
7.15 Lecture des tableaux de résultats
7.15.1 Figement des premières colonnes clés des tableaux de résultats
Afin de pouvoir se déplacer horizontalement dans les colonnes de grands tableaux de données, tout en conservant une vue sur les colonnes clés des lignes visualisées, les premières colonnes clés des tableaux de résultat des commandes Concordance (références), Table Lexicale, Spécificités et Index de partition (word / unités, F) sont figées horizontalement. C’est à dire qu’elles sont toujours visibles quels que soient les déplacements horizontaux.
Ci-dessous un exemple de Table Lexicale avec les deux premières colonnes (word, F) figées :
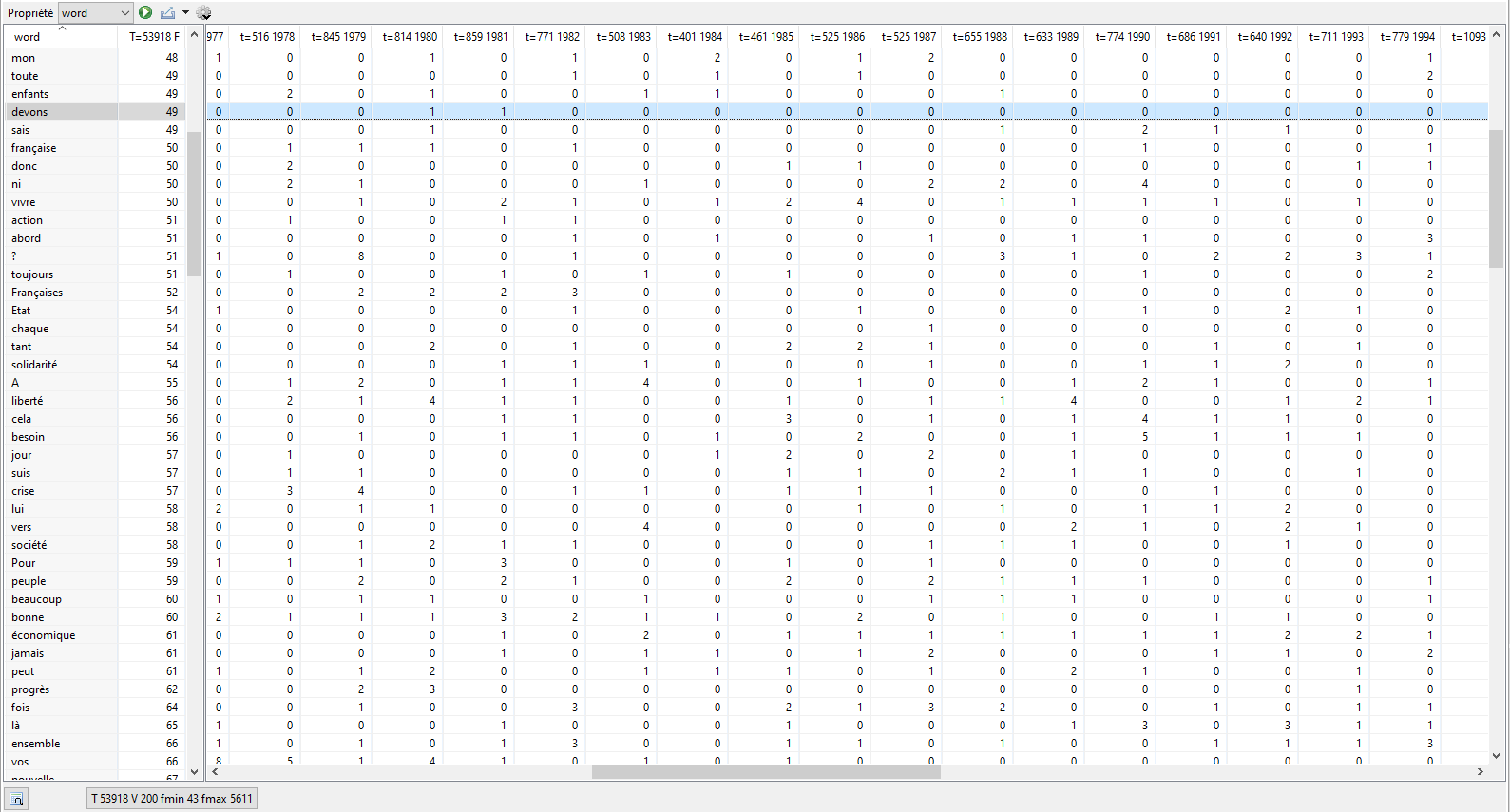
Figure 7.5: Exemple de table lexicale avec les premières colonnes figées.
7.16 Visualisations graphiques
Certaines commandes de TXM produisent des représentations graphiques dans des onglets dédiés. Ces onglets contiennent une barre d’outils spécifique à la visualisation et partagent des possibilités de manipulation des graphiques.
7.16.0.1 Manipulation interactive
Conventions de nommage :
« Ctrl- » signifie maintenir appuyée la touche Ctrl du clavier avec la touche correspondante pour les systèmes Windows et Linux ;
« Cmd- » signifie maintenir appuyée la touche Commande du clavier avec la touche correspondante sous Mac.
Vous pouvez interagir avec les graphiques de la façon suivante :
changement d’échelle : molette de la souris, ou Ctrl- « + » et Ctrl-« - » (Cmd- « + » et Cmd-« - »sous Mac)
translation de la vue : clic gauche et déplacement de la souris, ou flèches du clavier
revenir à la vue initiale : bouton de la barre d’outils de l’onglet des graphiques ou Ctrl-0 (Cmd-0 sous Mac)
7.16.0.2 Affichages complémentaires
Différentes informations sont affichées en info-bulle lorsque le curseur de la souris se trouve au dessus d’un élément du graphique (ex. barre, point, ligne). Ces données complémentaires dépendent du type de graphique (ex. AFC, dimensions de partition, etc.).
7.16.0.3 Mise en évidence et sélection d’éléments
Les éléments des graphiques peuvent être mis en évidence en utilisant le mécanisme de sélection. La sélection d’éléments fonctionne de façon analogue à celle des fichiers dans les explorateurs de fichiers du système d’exploitation (Remplacer « Ctrl- » par « Cmd- » sous Mac) :
clic gauche sur un élément : sélectionne l’élément de manière exclusive, en dé-sélectionnant les autres au besoin
Ctrl + clic gauche : ajoute ou retire un élément à la sélection
Màj + clic gauche : sélection étendue, ajoute ou retire tous les éléments jusqu’au dernier élément sélectionné dans le graphique
touche flèche gauche et touche flèche droite : cycle en sélectionnant les éléments de manière exclusive les uns à la suite des autres
Màj + flèches gauche et droite : sélection étendue : cycle en ajoutant ou retirant de la sélection les items les uns à la suite des autres
7.17 Exploitation des résultats
7.17.1 Exportation des résultats
Tous les résultats d’une commande TXM, sous forme de tableau ou de visualisation graphique, peuvent être exportés dans un fichier pour pouvoir être traité dans un autre logiciel (traitement de texte pour publication, tableur pour analyses complémentaires, etc.).
7.17.1.1 Export des tableaux
Les résultats sous forme de tableau sont exportés au format CSV : sélectionnez l’icone du résultat dans la vue « Corpus » et cliquez sur l’icone dans la barre d’outils, ou bien sur la commande « Exporter > Données… » dans le menu contextuel ou encore lancer la commande depuis le menu principal « Fichier > Exporter > Données… ».
Les caractéristiques du CSV, comme le caractère séparateur de colonnes, etc., peuvent être réglées dans la page de préférences « TXM > Utilisateur > Export ».
7.17.1.2 Export des graphiques
Les visualisations graphiques peuvent être exportées de deux façons :
exporter la vue courante : bouton de la barre d’outils des fenêtres de graphiques. Cette commande exporte la graphique tel qu’il apparaît dans la visualisation, c’est-à-dire en tenant compte des changements d’échelle, des déplacements latéraux effectués et des éventuels réglages du graphique.
exporter tout le graphique : à partir d’une icone de résultat de type « graphique » dans la vue « Corpus » (ex. AFC, CAH, etc.) par le biais de l’entrée « Exporter → Graphique… » du menu contextuel. Le graphique est exporté dans sa totalité.
Le format par défaut du fichier image (JPEG, PNG, BMP, GIF, SVG, PDF) peut être réglé dans la page de préférences « TXM > Utilisateur > Export ».
7.17.2 Traitement des résultats avec R
Pour les utilisateurs de R, il est possible de manipuler les résultats dans l’espace de travail de R. Certains résultats sont par défaut déjà disponibles dans l’environnement R : Spécificités, AFC, Classification, Progression, Table lexicale. Les autres peuvent être transférés à la demande avec la commande « Envoyer vers R » : lexique, index, concordance, corpus.
La façon d’accéder à ces résultats depuis R est documentée à la section Utilisation des résultats et objets TXM depuis R page 219.
7.17.3 Exploiter les graphiques de résultats dans d’autres logiciels
TXM produit les graphiques de résultats aux formats suivants :
Vectoriels
SVG - Scalable Vector Graphics
Format ouvert d’image vectoriel standardisé par le W3C http://www.w3.org/Graphics/SVG, http://fr.wikipedia.org/wiki/Scalable_Vector_Graphics ;PS - PostScript
Format propriétaire d’image vectoriel de la société Adobe Systems http://fr.wikipedia.org/wiki/PostScript ;PDF - Portable Document Format
Format propriétaire de document vectoriel de la société Adobe Systems http://fr.wikipedia.org/wiki/Portable_Document_Format ;Bitmaps
PNG - Portable Network Graphics
Format ouvert d’image bitmap compressé sans perte normalisé par l’ISO http://www.w3.org/TR/PNG, http://fr.wikipedia.org/wiki/Portable_Network_Graphics ;JPEG - Joint Photographic Experts Group
Format ouvert d’image bitmap compressé avec perte normalisé par l’ISO/CEI 10918-1 | UIT-T Recommendation T.81 http://fr.wikipedia.org/wiki/JPEG.
Le choix du format d’export se règle dans les Préférences : Préférences / Utilisateur / Export / Format des graphiques R par défaut.
Les formats vectoriels présentent l’avantage de pouvoir varier de taille sans perte de détails (zoom = agrandissement ou réduction général de l’image) et de pouvoir être édités par des logiciels spécialisés (par exemple pour ajuster la typographie en fonction de consignes éditoriales, pour améliorer la lisibilité en agrandissant ou réduisant les caractères sans changer l’échelle globale du graphique, pour déplacer la légende, etc.).
Nous recommandons :
le logiciel gratuit et open-source « InkScape » pour éditer le format SVG http://www.inkscape.org/fr ;
le logiciel commercial « Adobe Illustrator » pour éditer le format PS http://www.adobe.com/fr/products/illustrator.html.
TXM privilégie l’export des graphiques de résultats au format SVG.
Les formats bitmaps sont pris en charge par un plus grand nombre d’outils de travail et surtout sont plus faciles à manipuler dans les traitements de texte. Le format JPEG est un peu mieux pris en charge que PNG sous Windows. C’est donc le format le plus facile à manipuler en dehors de TXM, même s’il n’est pas encore très pratique à manipuler au sein de TXM lui-même (nous devons homogénéiser la façon avec laquelle il est exporté depuis TXM).
7.17.3.1 Import direct d’une image vectorielle au format SVG dans le traitement de texte LibreOffice Writer
produire et exporter un graphique dans TXM au format SVG. Par exemple :
dans TXM créer une partition dans le corpus DISCOURS appelée « loc » à partir de la structure « text » et son attribut « loc » ;
régler le champ « Préférences / Utilisateur / Export / Format des graphiques R par défaut » à la valeur « SVG » ;
lancer la commande «Dimensions» sur la partition « loc » ;
dans la barre d’outils de l’onglet des graphiques, cliquer sur le bouton , sélectionner le type « *.svg » dans la boîte de dialogue et sauver le graphique dans un fichier ;
importer l’image dans Writer :
dans Writer lancer la commande « Insertion / Image / À partir d’un fichier » ;
désigner le fichier SVG en navigant jusqu’à son dossier ;
l’image est alors insérée à l’endroit du curseur. Vous pouvez si nécessaire régler la taille de l’image avec la souris :
cliquer sur l’image → des poignées vertes de manipulation s’allument :
« Màj-clic » sur une des poignées et déplacer la souris fait varier la taille de l’image de façon homothétique (l’image n’est pas déformée) ;
cliquer sur l’image et déplacer la souris déplace l’image dans la page.
7.17.3.2 Import direct d’une image bitmap au format JPEG dans le traitement de texte LibreOffice Writer
produire et exporter un graphique dans TXM au format JPEG. Par exemple :
dans TXM créer une partition dans le corpus DISCOURS appelée « loc » à partir de la structure « text » et son attribut « loc » ;
lancer la commande «Dimensions» sur la partition « loc » ;
dans la barre d’outils de l’onglet des graphiques, cliquer sur le bouton , sélectionner le type « *.jpeg » dans la boîte de dialogue et sauver le graphique dans un fichier ;
importer l’image dans Writer :
dans Writer lancer la commande « Insertion / Image / À partir d’un fichier » ;
désigner le fichier JPEG en navigant jusqu’à son dossier ;
l’image est alors insérée à l’endroit du curseur. Vous pouvez si nécessaire changer la taille de l’image avec la souris :
cliquer sur l’image → des poignées vertes de manipulation s’allument ;
« Màj-clic » sur une des poignées fait varier la taille de l’image de façon homothétique (l’image n’est pas déformée).
7.17.3.3 Édition préalable d’un graphique au format SVG avec InkScape
produire et exporter un graphique dans TXM au format SVG. Par exemple :
dans TXM créer une partition dans le corpus DISCOURS appelée « loc » à partir de la structure « text » et son attribut « loc » ;
régler le champ « Préférences / Utilisateur / Export / Format des graphiques R par défaut » à la valeur « SVG » ;
lancer la commande «Dimensions» sur la partition « loc » ;
dans la barre d’outils de l’onglet des graphiques, cliquer sur le bouton , sélectionner le type « *.svg » dans la boîte de dialogue et sauver le graphique dans un fichier ;
éditer l’image dans InkScape:
ouvrir le fichier SVG depuis InkScape ;
avec la souris tracer un rectangle autour de la légende des ordonnées « Nombre de mots par partie » pour la sélectionner :
Utiliser la touche « flèche gauche » du clavier pour translater la légende vers la gauche (ou « cliquer-glisser » avec la souris sur la sélection) :
Vous pouvez alors sauvegarder votre travail pour un import ultérieur dans un traitement de texte.
7.18 Récapitulatif des relations entre commandes et résultats
Ces relations sont accessibles en général à partir du menu contextuel d’un résultat ou d’une icone.
| COMMANDES | DEPUIS | VERS | UTILISÉ PAR |
| AFC |
Partition Table lexicale |
||
| Classification | AFC | AFC | |
| Concordances |
Corpus Index Lexique Cooccurrences |
Édition | Cooccurrences |
| Cooccurrences | Corpus | Concordances | |
| Corpus | Import |
Cooccurrences Concordances Corpus Description Édition Index Lexique Partition Progression |
|
| Description | Corpus | ||
| Index |
Corpus Partition |
Concordances Progression |
Table lexicale d’une partition |
| Lexique | Corpus |
Concordances Progression |
|
| Partition | Corpus |
AFC Édition Index Spécificités Table lexicale |
|
| Progression | Corpus | ||
| Références | Corpus | Concordances | |
| Sous-Corpus | Corpus | Idem que Corpus + Spécificités | |
| Spécificités |
Partition Sous-corpus |
||
| Table lexicale |
Partition Index d’une partition |
AFC Spécificités |
|
| Édition |
Concordances
Corpus |
||
| Notice | Corpus |
7.19 Syntaxe des requêtes CQL
Cette section intègre des éléments d’un mémo CQL de Sophie Prévost pour le logiciel Weblex ainsi que du « mémo CQL » de Bénédicte Pincemin, 4 octobre 2012, Ateliers TXM.
7.19.1 Introduction
7.19.1.1 CQL, CQP
CQL est l’acronyme de Corpus Query Language, c’est un langage d’expression de requêtes. Une expression (ou équation) CQL est une chaîne de caractères exprimant un motif linguistique (un mot, ou une suite de mots) à partir des valeurs de leurs propriétés (comme la catégorie grammaticale, le lemme, la forme graphique).
CQP est l’acronyme de Corpus Query Processor, c’est un composant logiciel qui traite des requêtes : c’est un moteur de recherche qui permet de trouver toutes les occurrences correspondant à une équation CQL dans un corpus donné.
Le moteur CQP (Christ, Schulze, Hofmann, & Koenig, 1999) a été développé à l’origine à l’université de Stuttgart <http://www.ims.uni-stuttgart.de/projekte/CorpusWorkbench> et est désormais un logiciel libre <http://cwb.sourceforge.net>. Il est intégré à TXM où il assure les recherches d’occurrences de mots et de structures et, d’une façon générale, toutes les opérations de sélection à l’intérieur du corpus. Il a été choisi pour l’excellent rapport entre ses performances et la richesse d’expression des requêtes traitées.
7.19.1.2 Les requêtes dans TXM : requêtes simples, requêtes assistées, requêtes avancées
CQL est donc un langage formel, avec un lexique et une syntaxe d’opérateurs, qui forment un métalangage permettant de combiner des éléments pour la recherche de motifs structurés.
L’apprentissage du langage CQL n’est pas un passage obligé pour utiliser TXM, mais c’est en langage CQL qu’on a le mode d’expression de motifs le plus riche.
Si l’on saisit un mot dans la zone de requête, c’est interprété comme la recherche des mots présentant exactement cette graphie dans le corpus. Cela permet déjà un certain nombre de recherches simples. Mais on perçoit assez vite deux limites : d’une part, on reste à la « surface » du texte, on ne tire aucun parti des autres informations linguistiques encodées dans le corpus (lemme, catégorie grammaticale, etc). D’autre part, on est rivé à l’empan exact d’un mot : la formulation de la recherche ne peut se faire ni sur une partie du mot (son début par exemple), ni sur des expressions en plusieurs mots - alors que cela devient possible en utilisant CQL.
Le logiciel TXM comporte un assistant à l’écriture de requêtes, accessible via une icone « baguette magique » à gauche du champ de saisie de la requête. Cet assistant permet d’exprimer une recherche à l’aide de menus déroulants plus intuitifs si l’on est peu familier des langages de requête. En revanche, il ne permet pas d’exprimer autant de choses que le langage CQL, qui reste beaucoup plus souple et plus complet. La connaissance de CQL est donc utile pour avoir les possibilités d’expression les plus larges et les plus précises.
En pratique, on peut apprécier de combiner l’utilisation de l’assistant avec la connaissance du langage CQL. L’assistant peut faciliter l’écriture d’une première version de la requête. La connaissance de CQL permet ensuite de bien comprendre l’équation et de l’ajuster ou de l’affiner si nécessaire.
7.19.1.3 Dynamique de la construction d’une requête
Une requête se met au point : entre ce qu’on veut repérer (que l’on pense avoir exprimé dans la requête), et ce qu’on trouve effectivement dans le corpus, il y a souvent un écart qui demande à être corrigé. Il est de toutes façons toujours sage de vérifier la portée effective, dans le corpus choisi, de la requête utilisée, avant de l’utiliser pour un calcul statistique.
L’apprentissage et l’utilisation de CQL font donc un usage central de la fonctionnalité Index de TXM. La fonctionnalité Index permet de lister toutes les formes correspondant au motif dans le corpus. On peut les parcourir soit par importance quantitative décroissante (tri par fréquence décroissante, qui est la manière dont se présente le résultat par défaut), soit par ordre alphabétique, ce qui peut faciliter la lecture en regroupant les réalisations de forme proche.
Le parcours de cette liste des configurations trouvées met en évidence les formes indésirables ; en revanche il ne dit rien des formes qui seraient pertinentes mais qui, ne correspondant pas formellement à la requête, n’ont pas été repérées. Méthodiquement, on recommande donc toujours, quand on a un motif linguistique à rechercher, de commencer par l’exprimer de façon très ouverte, de veiller à minimiser les a priori qui pourraient être réducteurs. L’examen des occurrences correspondantes trouvées guide alors sur la manière d’ajouter alors peu à peu des contraintes permettant de cibler les formes pertinentes et d’écarter les formes non voulues.
7.19.1.4 Utilisation pédagogique des exemples
Les exemples ci-après ont été choisis pour illustrer les possibilités de CQL qui nous paraissent les plus utiles : il faut les soumettre à la fonctionnalité Index pour bien voir leur effet. Ils ont été conçus pour être lancés sur le corpus Voeux (http://sourceforge.net/projects/txm/files/corpora/voeux/voeux-bin-0.6.zip/download). Le corpus Discours est quelquefois utilisé en complément si nécessaire. Les exemples sur fond gris sont plus complexes et peuvent être ignorés dans un premier temps.
7.19.2 Recherche simple [niveau 1 (infralexical) : les valeurs]
7.19.2.1 Recherche d’un mot
bonheur
|
Pour chercher un mot donné il suffit de saisir sa graphie. |
Vive la République.
|
Pour chercher une séquence de mots ou de ponctuations on la saisit telle quelle.46. Cette requête est donc équivalente à la requête [word="Vive"] [word="la"] [word="République"] [word="\."] (voir plus bas)
|
amiamiti
|
Une partie d’un mot ne rapporte aucun résultat, l’expression doit correspondre à un mot entier attesté dans le corpus. |
| Trois façons équivalentes d’exprimer une recherche sur une graphie : | |
bonheur
|
- la graphie telle quelle |
"bonheur"
|
- la graphie entre guillemets doubles droits |
[word="bonheur"]
|
- l’usage des crochets et du mot réservé « word ». Les moyens les plus verbeux montreront leur utilité dans des cas plus complexes. |
|
|
Un blanc à l’intérieur des guillemets est significatif (partie intégrante de la graphie). Le guillemet doit être collé à la graphie cherchée (sans espace supplémentaire). |
[ word = "bonheur" ]
|
Les blancs à l’extérieur des guillemets ne sont pas significatifs et peuvent être utilisés pour faciliter la lecture. |
7.19.2.2 Variantes d’écriture
"gouvernement"%c |
Neutralisation de la casse (majuscules/minuscules). Les guillemets sont obligatoires. |
"Etat"%d |
Neutralisation des signes diacritiques (accents, cédille, etc.). |
"franc.*"%cd |
Les deux neutralisations peuvent être cumulées. |
7.19.2.3 Troncature et joker
|
|
Le point d’interrogation porte sur le caractère qui précède et signifie qu’il est facultatif (0 ou 1 fois). Il peut se placer n’importe où. C’est utile notamment quand le corpus n’est pas lemmatisé, ou que la qualité de la lemmatisation est insuffisante. |
nation.*
|
Point étoile à la fin = « mot qui commence par … » . Point = « un caractère, n’importe lequel ». |
.*patri.*
|
Etoile = « 0 à n fois, n aussi grand qu’on veut ». Utile pour chercher un radical. |
.+patri.*
|
Signe plus = « 1 à n fois ». Ici on impose qu’il y ait un préfixe. |
|
|
Ces opérateurs se plaçant n’importe où, on peut chercher des mots partageant les mêmes affixes, le radical variant librement. |
"i[mn].*ables?"
|
Les crochets sont pratiques pour indiquer l’ensemble des lettres possibles, une seule devant être choisie. |
.*
|
Zéro à n caractères, n’importe lesquels. Cette expression attrape tous les mots. |
.* .*
|
(dans Discours) Graphies incluant un blanc (au moins). |
.
|
Mots formés d’un seul caractère. |
...
|
Mots de longueur trois. |
7.19.2.4 Ponctuations
|
? |
Les caractères spéciaux (opérateurs), doivent être neutralisés en les précédant d’une barre oblique descendante, si on veut pouvoir les considérer eux-mêmes comme des caractères que l’on recherche. |
.*'
|
Ce n’est pas le cas de toutes les ponctuations : ex. ici mots terminés par une apostrophe. |
7.19.2.5 Classes de caractères
.+\p{P} |
Mot terminé par une ponctuation : permet d’attraper aussi les apostrophes obliques (souvent originaires de Word et qu’on ne peut pas saisir facilement au clavier dans TXM). |
\p{Lu}+ |
Mot composé de majuscules (y compris diacritiques). Voir FAQ pour autres classes. |
7.19.2.6 Alternative
paix|guerre |
OU, alternative non exclusive. Élargit la recherche à des variantes de formulation. |
(inter|supra)nation.* |
Peut s’utiliser à l’intérieur du mot, avec des parenthèses pour délimiter sa portée. |
(inter|supra)?nation.* |
Des opérateurs de facultativité ou répétition peuvent porter sur la parenthèse. |
7.19.3 Recherche sur les propriétés [niveau 2 (lexical) : les propriétés]
7.19.3.1 Introduction
Jusqu’alors, les recherches effectuées portaient sur la forme graphique des mots, qui est enregistrée dans la propriété word : [word=“bonheur”] signifie qu’on recherche la valeur bonheur de la propriété word, correspondant à la forme graphique. Mais, lorsque le corpus est enrichi, les mots portent d’autres informations que leur seule graphie, sous la forme d’autre propriétés. Les requêtes peuvent alors porter sur d’autres propriétés des mots (et les combiner).
La graphie étant une propriété (presque) comme les autres, tout ce qu’on a vu dans la section précédente s’applique aux valeurs de propriété quelle que soit la propriété, sauf l’écriture simplifiée.
Pour interroger sur les propriétés il faut connaître leur nom et leurs valeurs. En effet, le nom des propriétés dépend de l’import du corpus : dans tel corpus la propriété qui enregistre le lemme est lemma, dans tel autre frlemme, dans tel autre encore ttlemme, etc. De même, les valeurs des catégories grammaticales dépendent du jeu d’étiquettes utilisé. Dans TXM en version locale, la fonction Description montre quelles propriétés sont disponibles et donne pour chacune d’elle un aperçu de quelques valeurs attestées (sur les premières occurrences du corpus). La fonction Lexique permet de lister exhaustivement les valeurs d’une propriété attestées dans le corpus. Dans la version locale, un double-clic sur une de ces valeurs permet de voir son usage en contexte (dans une concordance). Ceci étant il est utile d’avoir les tables descriptives des jeux de catégories utilisés pour le corpus sur lequel on travaille.
7.19.3.2 Recherche sur une propriété
|
|
Rechercher un lemme permet de désigner un mot sous ses formes (très) variables. Il faut expliciter sur quelle propriété on travaille, la formulation à crochets devient nécessaire. |
[frlemma="je"]
|
Le lemme « je » recouvre ici ses formes élidées ou avec majuscule initiale. |
[frpos="ADV"]
|
De même, on peut chercher sur d’autres propriétés, comme la catégorie grammaticale. |
|
|
La valeur que prend la propriété peut utiliser les mêmes opérateurs que précédemment, par ex. pour reconstruire des catégories en regroupant des étiquettes. |
[frlemma=".*\|.*"]
|
Ici la barre verticale fait partie intégrante de l’étiquette (ambiguïtés latentes lors d’étiquetage TreeTagger_)._ |
7.19.3.3 Alternative (2)
[frpos="NAM|NOM"] |
Il y a plusieurs manières d’exprimer l’alternative, plus ou moins factorisées. |
[frpos="N(A|O)M"] |
La barre verticale est l’opérateur le plus général, sa portée peut être ciblée par des parenthèses. |
[frpos="N[AO]M"] |
Les crochets ne sont utilisables que pour une alternance sur un seul caractère, |
"[aeiouy]+" |
mais facilitent l’expression d’un large choix |
[pos=".*[1-3].*"] |
(dans Discours) ou d’une gamme. |
[pos="[^12]*"] |
(dans Discours) Le chapeau est une négation : ensemble des caractères interdits sur la position. |
[frpos="VER:(futu|cond|subi)"] |
Alternance sur des séquences de caractères (de longueurs identiques ou non) : seule la barre verticale est utilisable. |
7.19.3.4 Combinaison d’informations
[frlemma="pouvoir" & frpos="NOM"] |
Désambiguïsation catégorielle d’un lemme. |
[frpos="ADV" & word=".*ment"] |
Croisement d’une catégorie et d’un trait morphologique. |
[frlemma="liber.*"%d & frlemma!="libéral"] |
Exclusion de cas non souhaités. |
[frpos="NOM" & word!=".*\p{P}"] |
Post-taitement des erreurs de segmentation. |
[pos!="NA|pon" & pos!=fropos] |
(dans la BFM) Comparaison directe à une autre propriété. |
7.19.4 Recherche d’un motif de plusieurs mots [niveau 3 (supralexical) : séquences d’unités lexicales]
7.19.4.1 Succession de mots
[word="réduction"] [word="du"] [word="temps"] [word="de"] [word="travail"]
|
Paire de crochets = mot. |
|
|
Notation allégée possible si l’on ne travaille que sur des graphies. Mélange possible. |
[frpos="NOM"] [frlemma="de"] [frpos="NOM"]
|
Usage avec des catégories (patron). |
[frpos="NOM"] [frlemma="de"] [frlemma="le"]? [frpos="NOM"]
[frpos="NOM"] ([frlemma="de"][frlemma="le"]|[frlemma="du"]) [frpos="NOM"]
[frpos="DET.*"] [frpos="ADV"]? [frpos="ADJ"]+ [frlemma="année"]
On retrouve à ce niveau 3 les opérateurs vus au niveau 1, pour gérer les variations.
7.19.4.2 Traitement des insertions
[frlemma="il"] [] [frlemma="y"] [frlemma="avoir"]
|
Une unité lexicale quelconque (joker de mot). |
[frlemma="il"] []? [frlemma="y"] [frlemma="avoir"]
|
Insertion facultative. |
[frlemma="il"] [] [] [] [frlemma="y"][frlemma="avoir"]
|
Distance de trois unités lexicales. |
[frlemma="il"] []{0,3} [frlemma="y"] [frlemma="avoir"]
|
Distance de zéro à trois. |
|
|
Distance de 0 à 10, deux formulations équivalentes. |
Si l’on utilise []* il faut absolument borner l’expansion.
[frlemma="je"] [frpos!="V.*"]* [frlemma="souhaiter"] [frpos!="V.*"]* [frlemma="année"] within 25 |
Distances avec mots exclus, contrôle davantage syntaxique. |
[lemma="je"] [pos!="V.*"]* [lemma="souhaiter"] [pos!="V.*"]* [lemma="année"] within s |
(dans Discours) Empan sur structure (si disponible) |
[lemma="République"] []* [lemma="France"] within 2s |
(dans Discours) Structure multipliée. |
7.19.4.3 Étude distributionnelle
[frlemma="très"] |
On prend un motif (contexte), et on rend variable une place, soit complètement librement, |
[frpos="NOM"] [frlemma="français"] |
soit avec une indication de catégorie. |
[frlemma="ne"] [frpos="VER.*"] |
Recherche des verbes avec négation. |
[frlemma="ne"] ([frpos!="VER.*|NOM|ADJ"]|[frlemma="être|avoir"])* [frpos="VER.*" & frlemma!="être|avoir"] within 10
Idem, plus affinée.
7.19.4.4 Alternatives
([word="président"%c] [] [] [word="république"%c] | [word="chef"%c] [] [] [word="état"%cd])
Expressions.
([frlemma="paix"] []* [frlemma="monde"] | [frlemma="monde"] []* [frlemma="paix"]) within 10
([frlemma="travail.*"] []* [frlemma="famil.*"] | [frlemma="famil.*"] []* [frlemma="travail.*"]) within 20
Cooccurrences.
7.19.4.5 Expansion
[word="France"] expand right to 3 |
Étendre le résultat de 3 mots à droite |
[word="France"] expand left to 3 |
Étendre le résultat de 3 mots à gauche |
[word="France"] expand to 3 |
Étendre le résultat de 3 mots à gauche et de 3 mots à droite |
[word="France"] expand to 2 s |
Étendre le résultat à trois phrases : celle contenant le match, la précédente et la suivante |
7.19.5 Informations contextuelles
7.19.5.1 Utilisation des structures
|
|
(dans Discours) Verbes qui commencent une phrase. |
<s> [pos="V.*"] expand to s
|
(dans Discours) Phrases qui commencent par un verbe. |
<s> []{1,5} </s>
|
(dans Discours) Phrases d’au plus cinq mots. |
[pos="Vmsm.*"] expand to s
|
(dans Discours) Phrases contenant un motif donné (ici subjonctif imparfait). |
7.19.5.2 Utilisation d’une propriété de structure
[word="Algérie" & _.text_loc!="dg"] |
« Algérie » dans un texte dont le locuteur n’est pas De Gaulle. |
<sp_speaker="P"> [frpos!="PRO:PER"]* [frpos="PROPER"] |
Le premier pronom personnel de chaque tour de parole du professeur d’une transcription de cours. |
7.19.5.3 Utilisation des positions de mots dans le corpus
[word="France" & _>99]
|
Après le 100ème mot du corpus (les positions sont numérotées à partir de 0) |
[word=".*" & _=99]
|
Le 100ème mot du corpus |
|
|
Mots distants d’au moins 2 mots |
7.19.6 Les différentes stratégies de résolution des opérateurs itérateurs ?, * et +
Le nombre d’occurrences « attrapées » par les opérateurs ?, * et + dépend
de la stratégie de résolution courante du moteur de recherche CQP. Par
exemple, pour la requête suivante[54] :
[enpos="DET"]? [enpos="ADJ"]* [enpos="NN"] ([enpos="PREP"] [enpos="DET"]? [enpos="ADJ"]* [enpos="NN"])*
Avec le texte suivant à interroger :
the old book on the table in the room
On obtient les résultats suivants pour chaque stratégie :
- stratégie shortest : 3 matches
r1 = book
r2 = table
r3 = room
- stratégie longest : 1 match
r1 = the old book on the table in the room
- stratégie standard : 3 matches
r1 = the old book
r2 = the table
r3 = the room
- stratégie traditional : 7 matches recouvrants
r1 = the old book
r2 = old book
r3 = book
r4 = the table
r5 = table
r6 = the room
r7 = room
La stratégie de résolution par défaut est ‘standard’. Actuellement il faut utiliser la macro SetMatchingStrategy de la catégorie ‘cqp’ pour sélectionner la stratégie de résolution courante du moteur CQP, voir la section sXXX page pXXX.
7.19.8 Liens d’alignement entre corpus parallèles
On dispose d’un corpus latin CorpusLAT aligné avec un corpus d’ancien français CorpusFRO (textes existant dans les deux langues, en relation de traduction). Les requêtes suivantes sont effectuées sur CorpusLAT.
[lemme="HIC"] :CorpusFRO [lemme="CIST"] |
Occurrences du lemme HIC pour lesquelles on trouve le lemme CIST dans le passage aligné en ancien français. |
[lemme="HIC"] :CorpusFRO ! [lemme="CIST"] |
Occurrences du lemme HIC pour lesquelles on ne trouve pas le lemme CIST dans le passage aligné en ancien français. |
[lemme="HIC"] expand to seg :CorpusFRO [lemme="CIST"] |
Segments contenant le lemme HIC et pour lesquels on trouve le lemme CIST dans le segment aligné en ancien français. |
[] expand to seg :CorpusFRO [lemme="CIST"] |
Segments latins alignés avec ceux contenant le lemme CIST en ancien français (construction d’un sous-corpus pour calcul de résonance). |
<seg> [lemme!="HIC"]* </seg> :CorpusFRO [lemme="CIST"] |
Segments ne contenant pas le lemme HIC et pour lesquels on trouve le lemme CIST dans le passage aligné en ancien français. |
7.19.9 Documentation complémentaire
Pour une description complète du langage de requêtes CQL, vous pouvez consulter (en Anglais) :
- Oliver Christ, Bruno M. Schulze, Anja Hofmann, and Esther König,
« The IMS Corpus Workbench : Corpus Query Processor (CQP), User’s
Manual », August 16, 1999 (CQP V2.2), University of Stuttgart ,
<http://corpora.dslo.unibo.it/TCORIS/cqpman.pdf>
[tutoriel original (en Anglais)] - <https://docs.google.com/document/d/1rz39LixYl6uegx35kIj6JLYbMPEOsy2ycg4JuCBZ68Y>
[liste exhaustive de tous les opérateurs CQL]
7.20 Syntaxe des expressions régulières
L’expression des chaines de caractères dans les requêtes CQL suit la syntaxe des expressions régulières PCRE (Perl-Compatible Regular Expressions). La syntaxe complète est décrite à la section « Specification of the regular expressions supported by PCRE » du manuel de PCRE : http://regexkit.sourceforge.net/Documentation/pcre/pcrepattern.html.
Voici un résumé en français des opérateurs les plus courants.
. |
matche n’importe quel caractère |
\ |
neutralise l’opérateur situé à droite |
| |
alternance |
() |
regroupement |
[…] |
classe de caractères entre crochets (eg « [aeiouy] » pour une voyelle, ou « [a-z] » pour n’importe quelle minuscule) |
[^…] |
ensemble complémentaire de la classe de caractères entre crochets, le caractère ^ joue le rôle de négation (eg « [^aeiouy] » pour un caractère qui n’est pas une voyelle) |
Tableau 2: Méta-caractères (ou Opérateurs)
? |
matche 0 ou 1 fois l’expression située à gauche |
* |
matche 0 fois ou plus |
+ |
matche 1 fois ou plus |
{n} |
matche n fois |
{n,} |
matche au moins n fois |
{n,m} |
matche entre n et m fois |
Tableau 3: Quantifieurs
\x{CC} |
caractère de valeur CC (exprimée en hexadécimal) (eg « \x{E9} »pour « é ») |
\xCC |
caractère de valeur CC (exprimée en hexadécimal) |
Tableau 4: Codes de caractères
\d |
un chiffre |
\D |
pas un chiffre |
\w |
un caractère de « mot » |
\W |
pas un caractère de « mot » |
\s |
un caractère d’espace |
\S |
pas un caractère d’espace |
\p{Classe} |
un caractère de la classe Unicode « Classe » (eg « \p{Lu} » pour un caractère majuscule) |
\P{Classe} |
pas un caractère de la classe Unicode « Classe » |
[[:ClassePOSIX:]] |
un caractère de la classe « ClassePOSIX » (eg « [[:upper:]] » pour un caractère majuscule) |
Tableau 5: Classes de caractères
\p{L} |
lettre |
\p{Ll} |
caractère minuscule |
\p{Lu} |
caractère majuscule |
\p{N} |
caractère numérique |
\p{Xan} |
caractère alphanumérique |
\p{Pd} |
caractère de tiret (eg « - », « — »…) |
\p{P} |
caractère de ponctuation (eg « , », « . »…) |
\p{Ps} |
caractère de ponctuation ouvrante (eg « ( ») |
\p{Pe} |
caractère de ponctuation fermante (eg « ) ») |
\p{Sm} |
caractère de symbole mathématique (eg « ~ ») |
\p{Cyrillic} |
caractère en alphabet russe |
\p{Arabic} |
caractère en alphabet arabe |
\p{Greek} |
caractère en alphabet grec |
Tableau 6: Classes Unicode courantes[55]
alpha |
caractère alphabétique (usage : ”[[:alpha:]]”) |
alnum |
caractère alphanumérique |
ascii |
caractère du code ASCII |
digit |
chiffre décimal |
graph |
caractère imprimable, sans l’espace |
lower |
caractère minuscule |
print |
caractère imprimable, incluant l’espace |
punct |
caractère de ponctuation |
space |
caractère d’espace |
upper |
caractère majuscule |
word |
caractère de mot |
xdigit |
chiffre hexadécimal |
Tableau 7: Classes POSIX courantes (système plus ancien et plus grossier que les classes Unicode)
7.20.0.0.0.1 Références de caractères mémorisés
\2contenu du premier groupe de parenthèses mémorisé (suppose la présence de parenthèses « ..(..).. » auparavant dans l’expression)\3contenu du deuxième groupe de parenthèses mémorisé…
\g{nom}contenu du groupe de parenthèses mémorisé nommé « nom » (suppose la présence de « ..(?<nom>..).. » auparavant dans l’expression)…
Exemples :
([[:lower:]])([[:lower:]]).*m.*\3\2: deux minuscules suivies de « m » suivi des deux premières minuscules en ordre inverse ;(.*)\2: une même chaine deux fois de suite(?<groupe1>.*)\g{groupe1}: une même chaine deux fois de suite
depuis TXM 0.8.2, les séquences de mots ne contenant pas de caractères «
"», «[» ou «]» (respectivement le guillemet droit double, le crochet ouvrant ou le crochet fermant) sont segmentées comme du texte brut (TXT) en fonction de la langue du corpus pour déterminer les mots à chercher, facilitant la recherche par copié/coller de texte.↩︎