5 Importer un corpus dans TXM
Pour pouvoir appliquer des outils de TXM à un corpus de textes, il faut d’abord avoir introduit ce corpus dans TXM. C’est ce qu’on appelle l’importation d’un corpus dans TXM. L’importation consiste à lire les fichiers sources d’un corpus, situés dans un dossier du disque dur ou bien dans le presse-papier du système, pour en construire une représentation interne efficace qui sera utilisée par TXM pour réaliser tous les calculs demandés. Si l’import repose sur la lecture de fichiers de textes dans un dossier, le corpus peut être composé d’un ou de plusieurs textes. Si l’import est réalisé à partir du presse-papier, le corpus construit ne contient qu’un seul texte « virtuel », par construction.
5.1 Principes généraux
5.1.1 Quatre types de corpus textuels
La plateforme TXM est conçue pour importer et analyser quatre grands types de corpus textuels :
les corpus de textes écrits. Il s’agit de textes saisis à l’aide d’un traitement de texte comme Writer ou Word, ou bien issus de traitements de reconnaissance automatique de caractères (OCR : ABBYY FineReader…) appliqués aux images (scans) d’éditions sources au format papier. Les éditions TXM de sources numérisées peuvent typiquement être paginées et s’afficher de façon synoptique en regard des images de fac-similés (numérisations de manuscrits médiévaux ou d’auteur) ;
les corpus de transcriptions d’enregistrements. Il s’agit de textes transcrits avec l’aide de logiciels spécialisés pilotant la lecture des enregistrements, facilitant l’attribution de locuteur à chaque prise de parole et la synchronisation notamment, ou bien issus de traitements de reconnaissance automatique de la parole (speech-to-text : Vocapia…) appliqués aux fichiers d’enregistrement audio. Il peut s’agir également de textes saisis à l’aide d’un traitement de texte comme Writer ou Word en respectant quelques règles de formatage. Ces corpus peuvent typiquement être synchronisés, à la prise de parole ou au mot près, avec la source audio ou vidéo. Ce qui permet la lecture au sein de TXM de l’enregistrement audio ou vidéo au moment où un mot est prononcé ;
les corpus alignés (ou parallèles). Ces corpus alignent typiquement le texte d’une langue (ou d’une version d’un texte) avec celui d’une autre. Quand il s’agit de langues on parle de corpus multilingues. l’alignement est réalisé au niveau d’une structure textuelle comme la phrase ou le paragraphe. l’alignement permet de faire des recherches simultanées de mots au sein de deux versions d’un même texte en tenant compte des contraintes d’alignement ;
les corpus en tableau. Dans cette architecture de corpus, le contenu textuel a tendance à être de petite taille par rapport au nombre de métadonnées disponibles (les propriétés qui caractérisent le contenu textuel). Il peut s’agir de résultats d’enquêtes : LimeSurvey…, ou d’échanges au sein de réseaux sociaux : Tweets, SMS…).
5.1.2 Représentation interne d’un corpus : le modèle de corpus TXM
Quel que soit le type de corpus importé, sa représentation interne, appelée « modèle de corpus TXM », est toujours composée des éléments fondamentaux suivants :
des unités textuelles : chaque corpus est composé d’un ensemble de textes (livre, article, entretien…) pouvant avoir des propriétés appelées métadonnées (auteur, titre, date, genre…)
des structures textuelles optionnelles : chaque texte peut comprendre des structures internes imbriquées (sections, paragraphes, tours de parole…) pouvant avoir des propriétés (titre, numéro, locuteur…)
- des unités lexicales : chaque texte est composé d’une séquence de mots pouvant avoir des propriétés (forme graphique, lemme, catégorie grammaticale…). Les mots peuvent être imbriqués dans des structures textuelles et forment la plus petite unité du corpus.
À chaque unité textuelle correspond une édition du texte au format HTML destinée à la lecture cursive et au « retour au texte » depuis les commandes d’analyse pour une lecture précise. Selon le type de corpus, l’édition peut être paginée, disposer de mise en page, de styles ou encore d’illustrations intégrées sous forme d’images.
Dans les corpus de transcriptions d’enregistrement, les éditions peuvent par ailleurs être associées à des fichiers média audio ou vidéo, accessibles depuis le disque dur ou depuis un site web, pour permettre le « retour au média ».
Les corpus en tableau vont plutôt utiliser une seule édition pour l’ensemble du corpus, chaque texte disposant d’une structure interne propre et d’une page d’édition.
Les alignements de structures entre textes, dans les corpus alignés, sont des éléments supplémentaires spécifiques du modèle de corpus TXM.
L’importation d’un corpus est l’occasion d’équiper automatiquement chaque mot d’un texte avec son lemme et sa catégorie grammaticale à l’aide de logiciels de traitement automatique de la langue (TAL) comme TreeTagger.
Enfin, les modules d’import les plus évolués peuvent adapter leurs traitements en fonction de différentes parties de chaque texte pour construire ce qu’on appelle les plans textuels. Ils peuvent par exemple ignorer des parties (le « hors texte »), éditer des parties sans que leurs mots soient indexés par le moteur de recherche, éditer certaines parties sous forme de notes de bas de page, etc.
5.1.3 Philologie numérique progressive : choix du niveau de représentation textuelle à importer
L’environnement d’importation des sources de TXM est conçu de sorte à pouvoir choisir un niveau de représentation des sources adapté, plus ou moins riche et donc plus ou moins coûteux à préparer, en fonction des besoins d’analyse. Ces représentations s’organisent en trois niveaux, du plus simple au plus riche :
TXT : texte brut
Le texte brut est la représentation la plus élémentaire d’un texte qui prend la forme d’une séquence de caractères et d’espaces. Elle peut être importée dans TXM et déjà offrir tous les services d’analyse de base. Tous les formats textuels peuvent être convertis14 en TXT pour pouvoir bénéficier de ce premier type d’import (PDF, MS Word, LibreOffice Writer, etc.). Le système d’encodage des caractères privilégié dans TXM pour le texte brut est l’encodage Unicode UTF-8 (Unicode Consortium, 1996) ;XML : texte encodé avec des balises XML
Si cela s’avère pertinent, les sources peuvent être augmentées dans un second temps en une représentation plus riche, comme par exemple avec un balisage XML (Bray, Paoli, Sperberg-McQueen, Maler, & Yergeau, 2008a)15. Le XML est une représentation en texte brut augmentée de règles syntaxiques strictes définissant des balises permettant d’encadrer et de qualifier des portions de texte, ces balises pouvant s’imbriquer pour former un modèle arborescent strict d’un texte. Un corpus peut être encodé minimalement en XML et être ré-importées dans TXM pour bénéficier de possibilités de manipulation et d’analyse supplémentaires (disponibilité de structures internes et de leurs propriétés, pré-codage de certains mots, etc.). Le nombre et le type de balises XML encodés au sein d’un texte est à la discrétion de l’utilisateur, en fonction des services dont il souhaite pouvoir bénéficier au sein de TXM. l’utilisateur peut ajouter progressivement les balises dont il a besoin.TEI : texte encodé en XML selon les recommandations du consortium de la Text Encoding Initiative (TEI Consortium, 2017)
À partir du moment où l’on investit dans l’encodage XML, il devient intéressant de commencer à appliquer certains principes du consortium TEI pour l’encodage XML. Cela permet non seulement de manipuler un XML compréhensible par une grande communauté d’utilisateurs (ce qui le rend inter-opérable et réutilisable entre projets et entre logiciels) et pérenne (repérable au sein de catalogues et archivable), mais également de bénéficier de services supplémentaires de TXM (comme le réglage de la construction des éditions, d’éditions synoptiques, de l’accès local ou distant aux images de fac-similés, la mise en œuvre de plans textuels, etc.)
Avec TXM on peut moduler l’investissement dans la préparation des sources en fonction des besoins d’analyse. Par exemple on peut commencer en texte brut et s’y limiter si les analyses obtenues sont satisfaisantes ou bien investir dans une représentation un peu plus riche, si les services rendus par TXM à l’aide des éléments supplémentaires sont particulièrement utiles ou nécessaires. Le tableau 5.1 synthétise les différents niveaux de services offerts par la plateforme en fonction du niveau de représentation des sources choisi :
| 1. TXT | 2. XML/w | 3. XML-TEI | |
|---|---|---|---|
| Unités Textuelles | fichiers | fichiers* | fichiers* |
| Métadonnées | CSV | CSV | <teiHeader> |
| Mots | brut | <w>? |
<w>? |
| Structures | - | toutes | spécifique |
| Plans textuels | - | XSL frontale | spécifique |
Les trois colonnes de droite représentent les niveaux de représentation des sources :
« TXT » du texte brut importé par le module d’import
TXT + CSV;« XML/w » du texte encodé en XML « tout venant »16 importé par le module
XML/w + CSV17 ;« XML-TEI » du texte encodé en XML utilisant certains éléments TEI importé par un module comme
XML-TEI Zero + CSV.
Chaque ligne représente un des services obtenus pour l’exploitation du modèle de corpus de TXM en fonction du niveau de représentation des sources :
Unités textuelles : les trois niveaux de représentation de sources créent des unités textuelles. Ces unités correspondent toujours aux fichiers contenant les textes. Pour chaque fichier source il y aura un texte et une édition dans le corpus. Les deux derniers niveaux (*), XML et XML-TEI, permettent de construire les fichiers pris en compte par TXM à l’aide de traitements intermédiaires à la volée à partir de sources d’architectures diverses (plusieurs textes par fichier ou plusieurs fichiers pour un même texte…) ;
Métadonnées : les deux premiers niveaux de représentation importent les métadonnées de textes par le biais d’un tableau de métadonnées (symbolisé par CSV) obligatoirement nommé « metadata » (voir section ci-dessous). Dans le troisième, en TEI, les métadonnées peuvent provenir d’un encodage dans la balise
<teiHeader>. Le fichier « metadata » n’est pas obligatoire pour réaliser un import, donc l’utilisateur peut l’encoder et le fournir ou non suivant ses besoins d’analyse. En général, on importe des métadonnées quand on a besoin de comparer des textes ou des ensembles de textes entre eux, ou quand on a besoin d’indications bibliographiques précises (auteur, date, titre, genre…) pour situer les résultats de recherches de mots. La métadonnée minimale, toujours présente dans un corpus même en l’absence de fichier « metadata », est l’identifiant (unique) du texte. La disponibilité de diverses métadonnées de textes constitue une dimension supplémentaire de progression philologique ;Mots : Au premier niveau, en texte « brut », les mots ne peuvent qu’être calculés automatiquement par TXM en fonction du système d’écriture utilisé par le corpus. Dans les deux niveaux suivants, en XML et en XML-TEI, il est possible de pré-coder de façon précise la délimitation et les propriétés de certains ou de tous les mots du corpus avec une balise
<w>(le? symbolise le fait que les balises<w>sont optionnelles). Remarque : le pré-codage optionnel de mots, à ne réaliser que si cela est utile à l’analyse, est une troisième dimension de progression philologique ;Structures : n’ayant pas de mécanisme de délimitation particulier, le texte brut ne peut pas disposer de structures textuelles (symbolisé par -). En XML tout venant, toutes les délimitations par balises correspondent à des structures textuelles, sauf la balise
<w>réservée aux mots. En TEI les balises ont des rôles spécifiques, comme celles correspondant aux structures textuelles. Remarque : En XML, le balisage progressif, à ne réaliser que si cela est utile à l’analyse, est une quatrième dimension de progression philologique ;Plans textuels : le texte brut n’ayant pas de mécanisme de délimitation aucun plan textuel n’est mobilisable (symbolisé par -). En XML, le module d’import
XML/w + CSVpropose d’appliquer n’importe quelle feuille de transformation XSLT sur les sources avant de les traiter (la XSL frontale). De cette façon, la XSL va permettre de calculer par exemple le « hors texte » à la volée18. Le module d’importXML-TEI Zero + CSVquant à lui offre 4 phases successives de transformation XSLT pendant l’import pour offrir plus de possibilités de manipulation de plans textuels. En encodage XML-TEI, certaines balises pourront correspondre à des plans textuels spécifiques.
5.1.4 Carte des modules d’import et de l’imbrication des niveaux de représentation
Les trois niveaux de représentation sont imbriqués au sens où l’imbrication d’un niveau dans un autre signifie qu’il est de même nature et bénéficie des mêmes services que celui dans lequel il est imbriqué. Plus un niveau est imbriqué profondément plus la représentation correspondante est explicite et normalisée :
Unicode TXT : le format texte brut, correspondant au périmètre le plus externe, est le format le plus élémentaire : une séquence de caractères et d’espaces ;
XML : le format XML est du texte brut, c’est à dire qu’il s’agit d’une séquence de caractères, mais ayant des contraintes supplémentaires comme la convention de la syntaxe des balises pour délimiter et qualifier des parties de texte ;
TEI : le format TEI est du XML, c’est à dire qu’il s’agit d’un texte brut balisé, mais ayant des contraintes supplémentaires comme la convention de nommage, de positions respectives et de sémantique des balises.
Les modules d’import de TXM sont les composants logiciels qui réalisent concrètement le travail de transformation des fichiers sources en une représentation interne du corpus. Ces modules peuvent prendre les sources à différents niveaux de représentation et la figure 5.1 en fait la cartographie par rapport à l’imbrication des trois niveaux de représentation.
Pour chaque module d’import, la figure représente à l’aide de flèches la chaîne de transformations depuis les formats externes des sources jusqu’au format interne « XML-TEI TXM » propre à TXM.
Le processus d’import peut être vu comme une transformation des sources depuis un format de départ plus ou moins riche et précis (les différents formats correspondent à des rectangles blancs dans la figure), en suivant les flèches correspondants aux différents modules d’import disponibles (représentés par des rectangles à la bordure épaisse : en blanc les corpus écrits, en bleu les corpus de transcriptions d’enregistrements et en corail les corpus alignés), jusqu’au format « XML-TEI TXM » qui est un format compatible avec les recommandations standard de la TEI et suffisamment spécialisé pour être directement traitable par les outils de TXM.
À partir du moment où les sources d’un corpus sont dans ce format,
les outils d’indexation et de construction d’éditions peuvent finaliser
directement la représentation interne du corpus (représentée par le
rectangle gris et blanc le plus à droite TXM — CQP | HTML5 dans le cercle brun le plus foncé).
La représentation XML-TEI TXM est la plus explicite et la plus normalisée de l’environnement d’import de TXM, et tous les corpus importés dans TXM sont représentés sous cette forme normalisée à la fin de l’import quel que soit leur format source de départ.
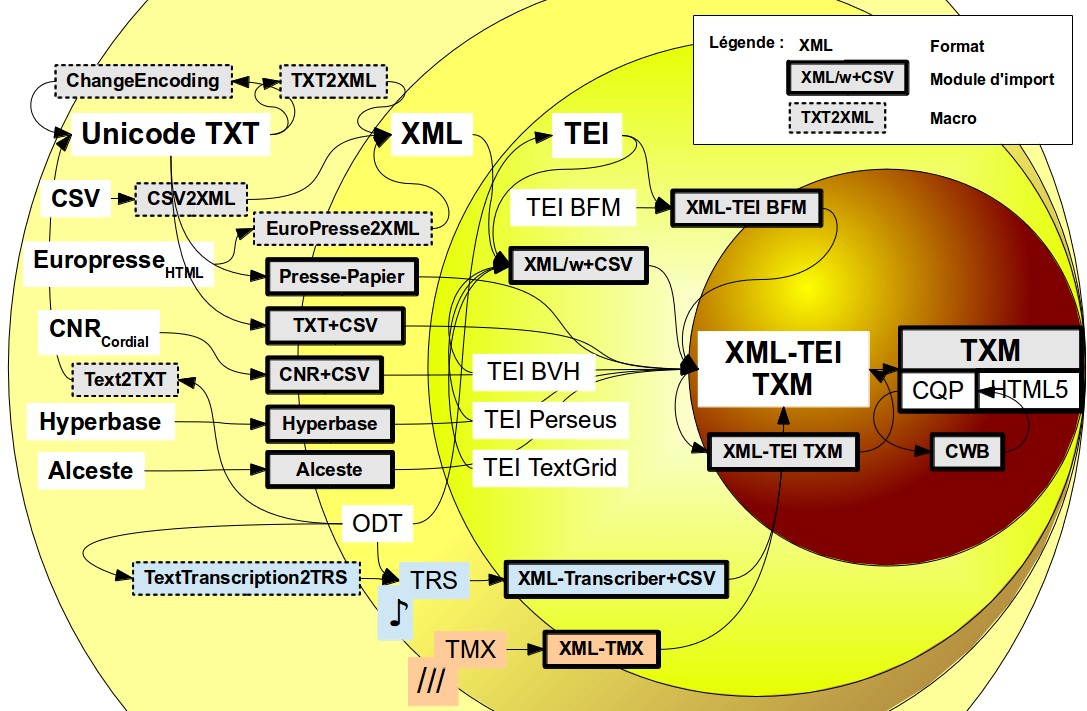
Figure 5.1: Carte des modules d’import par niveau de représentation textuelle TXTXMLTEI.
5.1.5 Fonctionnement d’un module d’import
Tous les modules d’import suivent une séquence d’opérations similaire.
Par exemple le module d’import de textes au format texte brut (TXT + CSV)
est composé de la succession d’opérations de normalisation suivante :
récupérer les fichiers d’extension « .txt » du dossier source ;
transformer le contenu en XML et ajouter éventuellement les métadonnées aux textes à partir du fichier « metadata » qui se trouve dans le dossier des sources ;
créer la version pivot XML-TEI TXM des textes ;
créer une représentation des textes compatible avec le logiciel TreeTagger et, si nécessaire, avec chaque logiciel de TAL utilisé, puis après avoir appliqué le logiciel aux textes, injecter les résultats dans les représentations XML-TEI TXM ;
indexer les mots et créer les éditions de textes ;
à ce moment là le corpus est disponible dans TXM pour être exploité : partitionner, créer des sous-corpus, manipuler les structures internes des textes et les mots accompagnés de leurs propriétés.
5.2 Import depuis le presse-papier ou d’un dossiers de fichiers sources
Pour créer un nouveau corpus dans TXM on lance un module d’import à l’aide d’une des commandes du menu « Fichier > Importer ».
Tous les modules d’import prennent en entrée un chemin vers le dossier contenant les fichiers sources du corpus, sauf le module d’import « Presse-papier » qui utilise directement le contenu du presse-papier du système d’exploitation.
5.2.1 Import depuis le presse-papier
L’import presse-papier est la façon la plus simple et la plus rapide, mais aussi la plus limitée, de créer un corpus dans TXM. Il suffit :
d’abord de copier n’importe quel texte depuis un logiciel19, ce qui se fait en général par :
puis ensuite de lancer la commande TXM « Fichier > Importer > Presse-papier ».
Le résultat est un nouveau corpus ayant un nom calculé automatiquement « PRESSEPAPIERnn » composé d’un seul texte (factice) contenant les mots trouvés dans le presse-papier interprété comme du texte brut. Si l’extension TreeTagger est installée, les mots sont également lemmatisés selon la langue choisie dans la préférence « TXM / Utilisateur / Import / Clipboard / Default language ».
5.2.2 Import de fichiers sources depuis un dossier
On appelle un des modules du menu « Fichier > Importer » selon le format des fichiers sources (TXT, XML, TEI, etc.) :
| Module | Format |
|---|---|
| TXT + CSV | fichiers de texte brut (.txt) + tableau de métadonnées22 (metadata)23 |
| ODT/DOC/RTF + CSV | fichiers de traitement de texte (.docx, .odt, .rtf, etc.)24 |
| XML/w + CSV | fichiers XML (.xml) |
| XML-TEI Zero + CSV | fichiers XML avec des balises TEI optionnelles |
| XML-TEI BFM | fichiers XML-TEI de la Base de Français Médiéval (BFM) |
| XML-TEI Frantext | fichiers XML-TEI libres de droits de Frantext |
| XML-TEI TXM | fichiers XML-TEI normalisés pour TXM |
| XML Transcriber + CSV | fichiers XML de transcription selon le schéma XML du logiciel Transcriber |
| XML Factiva | fichiers exportés au format XML depuis le portail Factiva |
| XML-TMX | fichiers XML selon le schéma XML TMX de corpus multilingues alignés (mémoires de traduction) |
| Factiva TXT | fichiers exportés au format TXT depuis le portail Factiva |
| Cordial + CSV | fichiers résultat du logiciel Cordial |
| IRaMuTeQ / Alceste | fichiers au format étoilé (****) des logiciels IRaMuTeQ et Alceste |
| Hyperbase | fichiers au format Hyperbase (&&&) |
| CQP | fichiers au format tabulé de CQP |
5.3 Paramètres d’import généraux
Au lancement d’un module d’import, son formulaire de paramètres s’ouvre, similaire à celui de la figure 5.2 :
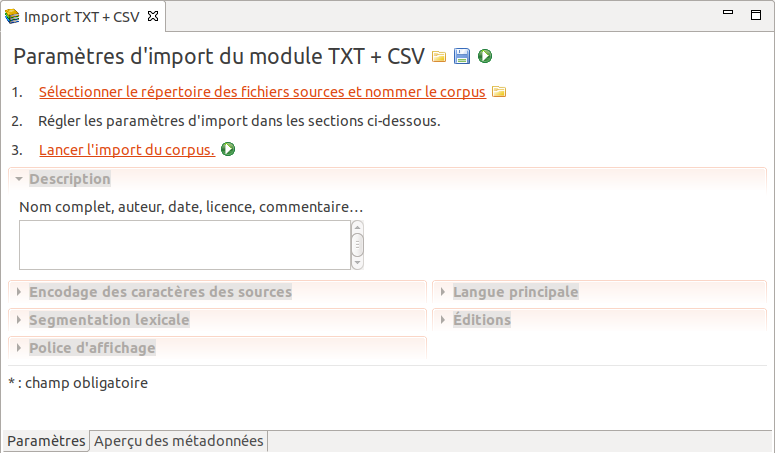
Figure 5.2: Formulaire vide des paramètres du module d’import TXT + CSV.
Il faut commencer par sélectionner le dossier des sources et indiquer l’identifiant du nouveau corpus en cliquant sur le lien “Sélectionner le dossier des fichiers sources et nommer le corpus” (ou bien sur l’icone de dossier) qui ouvre la boite de dialogue figure 5.3 :
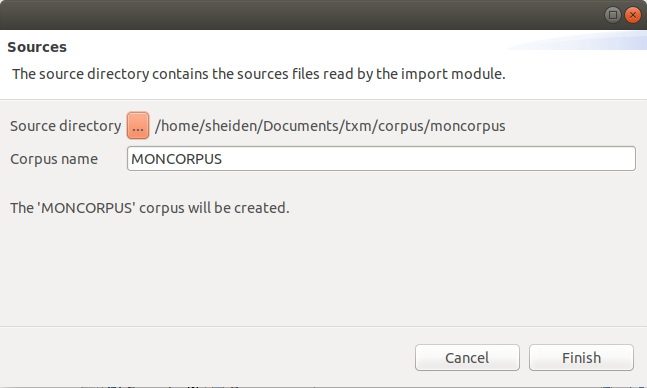
Figure 5.3: Désignation du dossier des sources et nommage du corpus.
Le bouton « […] » permet de désigner le dossier des sources.
Le nom à saisir pour l’identifiant de corpus doit suivre des règles strictes :
- ne pas commencer par un chiffre ;
- puis n’utiliser que des caractères majuscules sans accents ou diacritiques, des chiffres ou le tiret (-) ;
- ne pas dépasser une longueur de 20 caractères.
Exemples :
- MONCORPUS
- MONCORPUS1
- MONCORPUS-1
- MON-CORPUS-2
Tant que ces règles d’identifiant ne sont pas respectées, la boite de dialogue ne peut se fermer.
Une fois ces renseignements fournis, les autres sections de paramètres sont activées, comme dans la figure 5.4 :
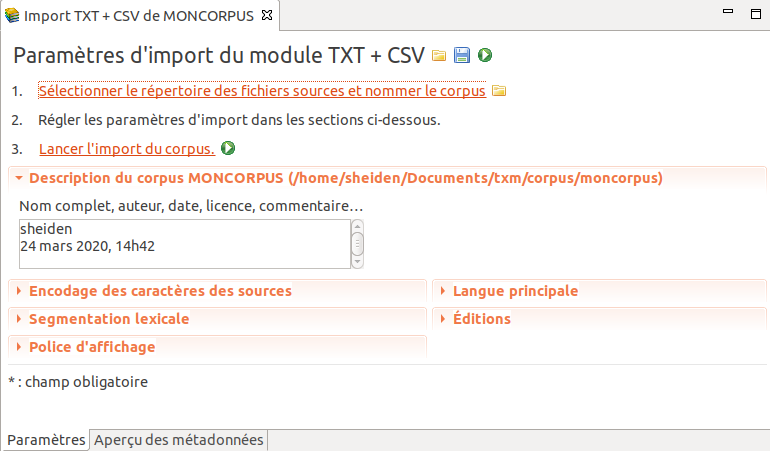
Figure 5.4: Paramètres du module d’import TXT + CSV.
Il faut ouvrir les différentes sections de paramètres, en cliquant sur leur intitulé, pour y accéder.
La dénomination des sections de paramètres dépend du module d’import utilisé.
5.3.1 Description du corpus
On peut associer au corpus une description optionnelle en format libre :

Figure 5.5: Paramètre Description du corpus.
La valeur par défaut de ce paramètre reprend l’identifiant de l’utilisateur réalisant l’import, la date et l’heure.
Il est recommandé d’ajouter d’autres informations utiles à l’utilisation du corpus, comme par exemple : le nom complet du corpus, l’auteur, la date de création, le numéro de version du corpus, la licence de diffusion, des commentaires, etc.
De tels renseignements sont utiles par exemple quand on manipule différentes versions d’un même corpus ou bien pour associer une documentation à un corpus.
On peut utiliser des balises HTML pour la mise en forme du texte (mise en gras, italique, intertitres, etc.).
5.3.2 Encodage des caractères des fichiers source
Cette section ne concerne que les modules d’import de fichiers au format texte brut (TXT + CSV, IRaMuTeQ / Alceste, Hyperbase, Factiva TXT, CQP).
Remarque : le paramètre de choix d’encodage des caractères n’est pas disponible dans les modules d’import basés sur XML car la détermination de l’encodage des caractères est pris en charge au sein des fichiers source par le standard XML25.
En général, on s’intéresse à l’encodage des caractères quand certains caractères des textes d’un corpus ne s’affichent pas correctement dans TXM. Si les caractères ne s’affichent pas correctement, c’est que TXM n’a pas compris quel encodage de caractères était utilisé dans les fichiers source.
Le paramètre d’import Encodage des caractères permet de préciser - si nécessaire - le système d’encodage des caractères utilisé par les fichiers sources :
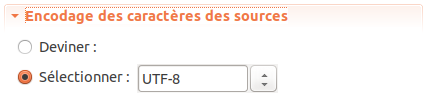
Figure 5.6: Paramètre Encodage des caractères.
Le paramètre Sélectionner prend la valeur « UTF-8 » par défaut, ce qui correspond au standard Unicode.
Il ne faut modifier cette valeur que si l’encodage utilisé par les textes est différent de l’encodage Unicode UTF-8.
De plus en plus de systèmes d’exploitation et de logiciels produisent et gèrent des textes encodés en Unicode UTF-8, donc dans la plupart des cas il n’est pas nécessaire de modifier ce paramètre.
Pour des fichiers plus anciens26, le système d’encodage des caractères utilisé peut varier selon les systèmes d’exploitation et selon les pays pour lesquels ils ont été créés. Dans ce cas, il faut préciser le système d’encodage de caractères utilisé effectivement par les fichiers source.
Les encodages « historiques » par défaut des systèmes d’exploitation sont les suivants :
- sous Windows : encodage « cp1252 » en Europe ou « cp1250 » aux États-Unis ;
- sous Mac OS X : encodage « MacRoman » ;
- sous Ubuntu : encodage « UTF-8 »
On peut également trouver des fichiers encodés dans des systèmes d’encodage normalisés « historiques » plus récents27 précurseurs d’Unicode et dépendants de la zone linguistique :
- pour l’Europe occidentale : le système ‘ISO Latin 1’ (appelé également ‘ISO-8859-1’, ou ‘Latin-1’ ou encore ‘Europe occidentale’ selon les logiciels et les systèmes d’exploitation)
- Europe centrale : ISO-8859-2
- Europe du Nord : ISO-8859-4
- Cyrillique : ISO-8859-5
- Arabe : ISO-8859-6
- Grec : ISO-8859-7
- Hébreu : ISO-8859-8
- etc. (voir la liste de tous les systèmes d’encodage de la norme ISO 8859)
Si l’encodage varie en fonction des textes, ou si vous ne savez pas quel encodage choisir, vous pouvez cocher l’option Deviner. Dans ce cas TXM essaiera de déterminer automatiquement l’encodage des textes28. Comme le calcul d’encodage se trompe assez facilement, cette option est à utiliser avec prudence.
5.3.2.1 Déterminer l’encodage des caractères de vos fichiers source
Pour aider au diagnostic de l’encodage des caractères de vos fichiers source, l’utilitaire txt / CharList (txt / CharListDirectory pour un dossier de fichiers) liste tous les caractères présents dans un fichier et leur fréquence. Si les caractères sont bien tous correctement listés par cet outil c’est que l’encodage choisi en paramètre est le bon.
Pour connaitre tous les encodages de caractères disponibles sur votre machine, l’utilitaire txt / ListEncodings affiche les noms de tous les encodages de caractères connus (et leurs alias).
Suivant l’historique des manipulations d’un fichier .txt, il est possible également que l’encodage des caractères varie au sein d’un même fichier. Cela arrive quand les réglages du logiciel d’édition n’étaient pas corrects et que des portions de texte dans un encodage différent ont été ajoutés au fichier. Dans ce cas aucune conversion globale de caractères (comme ce qui est réalisé par l’utilitaire txt / ChangeEncoding) ne pourra produire un fichier avec un encodage correct. Il faudra isoler chaque partie ayant un encodage propre, la convertir indépendament des autres, puis recomposer le fichier.
Quand vous avez épuisé toutes les conversions d’encodage possibles, c’est peut-être que votre fichier est dans cet état.
5.3.2.2 Encodage préalable définitif des fichiers source en UTF-8
Il est possible de régler une fois pour toutes l’encodage des caractères des fichiers source d’un corpus en amont de l’import dans TXM,
à l’aide de l’utilitaire txt / ChangeEncoding qui modifie par lots l’encodage des caractères de tous les fichiers d’un dossier de sources.
L’utilitaire est documenté
dans la page de documentation des utilitaires de TXM.
Une fois les sources encodées en Unicode UTF-8, il n’est plus
nécessaire de régler le paramètre d’import « Encodage des
caractères » à une autre valeur que UTF-8.
5.3.3 Langue principale
Cette section concerne la langue principale du corpus :
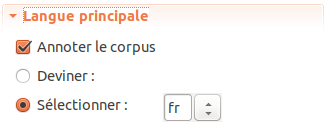
Figure 5.7: Paramètre Langue principale.
On trouve régulièrement des éléments de langues « secondaires » (étrangères) dans les textes : emprunt lexical, locution, citation… Malgré cela, une seule langue est gérée à la fois par corpus, en ce qui concerne le TAL et l’ordre lexicographique des mots. Sauf pour les corpus alignés multilingues bien sûr.
Le paramètre Annoter le corpus sert à piloter l’application du logiciel TreeTagger sur les sources. Le logiciel TreeTagger est un outil de traitement automatique de la langue (TAL) qui attribue automatiquement une catégorie grammaticale et un lemme à chaque mot d’un texte, en fonction de sa langue.
Remarque : les taux d’erreurs d’attribution de catégories et de lemmes de logiciels comme TreeTagger sont de l’ordre de quelques pourcents et dépendent des langues29.
Par exemple, pour le français un taux moyen de 2% d’erreurs produira environ 10 mots avec une mauvaise catégorie grammaticale voire un mauvais lemme par page de 500 mots. Certaines catégories grammaticales ont de moins bonnes performances que d’autres et certains lemmes peuvent être systématiquement faux.
Même s’il n’y a pas de réponses absolues à toutes les questions de catégorisation grammaticale et de lemmatisation, ces informations offrent des services particulièrement utiles à l’analyse textométrique d’un corpus, notamment pour l’accélération des dépouillements en masse. Il est donc recommandé de développer un avis critique sur ces informations pour chaque corpus, même s’il est malgré tout toujours possible à tout moment d’utiliser TXM sans ces informations, en n’utilisant que les mots et leur forme graphique. Les outils Lexique et Index sont précieux pour réaliser un diagnostic d’annotations lexicales. En particulier l’outil Index permet de focaliser les diagnostics sur des mots ou des séquences de mots ayant une forme, une catégorie ou un lemme pour lesquels on a un doute.
Pour certains corpus il peut être intéressant d’investir dans l’amélioration préalable de ces informations, notamment dans le cas de corpus « captifs » développés sur le long terme par plusieurs projets de recherche, en corrigeant la catégorie grammaticale ou le lemme de certains mots avec les outils d’annotation de mots par concordances de TXM, voir la section ?? page ??. Pour les corpus à durée de vie plus limitée, on pourra trouver un compromis entre l’investissement dans le travail de redressement de certaines de ces informations et dans celui du travail d’analyse en fonction de la gêne provoquée par les erreurs d’annotation.
Décocher le paramètre Annoter le corpus sert à accélérer le temps d’importation, utile par exemple quand on est en train de mettre au point l’import d’un corpus, quand aucun modèle de langue TreeTagger n’est disponible pour le corpus ou encore quand l’extension TreeTagger n’est pas installée.
Le paramètre Sélectionner (la langue) sert à déterminer le modèle de langue qui sera appliqué par TreeTagger et l’ordre lexicographique dans les résultats de TXM (pour les tris alphabétiques).
Le code de langue utilisé dans le champ [fr ] est organisé selon le standard à deux lettres ISO 639-1.
Si le code de la langue souhaitée n’apparaît pas dans le menu - alors que vous avez bien installé le fichier de modèle dans le répertoire de modèles TreeTagger - éditez le champ où apparaît le code « fr » et ajoutez le code ISO 639-1 de la langue ajoutée (« de » pour allemand, « it » pour italien, etc).
Le modèle linguistique utilisé par TreeTagger correspond au fichier nommé <code de langue>.par situé dans le dossier des fichiers de modèles linguistiques. Par exemple, pour le français moderne, le code de langue est « fr » et le fichier de modèle linguistique utilisé sera fr.par. Pour qu’un fichier de langue donnée soit disponible dans le dossier des fichiers de modèles linguistiques il faut l’avoir installé au préalable : voir la section @ref(sec:installation-modèle-langue-TreeTagger) page @ref(page:installation-modèle-langue-TreeTagger).
Remarque : Il est possible de nommer les fichiers de modèle de langue de TreeTagger sans utiliser de code ISO 639-1. Par exemple, pour le français médiéval, vous pouvez nommer le fichier de modèle fro.par30. Dans ce cas, pour l’utiliser par le biais du module d’import, il faudra cliquer avec la souris directement dans le champ [fr ] du paramètre Sélectionner pour saisir la chaîne « fro ». L’ordre lexicographique dans les résultats de TXM sera indéterminé dans cette configuration.
Comme pour le paramètre d’encodage des caractères, l’option Deviner essaiera de déterminer la langue des textes automatiquement. Comme le calcul de la langue se trompe assez facilement, cette option est a utiliser avec prudence.
5.3.4 Segmentation en phrases et en mots
La section « Segmentation lexicale » permet de régler le repérage automatique par défaut des limites de phrases orthographiques et des mots à l’aide de quatre paramètres :
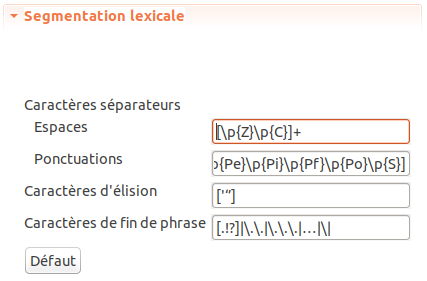
Figure 5.8: Paramètre Segmentation lexicale.
Les valeurs par défaut de ces paramètres produisent des résultats acceptables pour tous les systèmes d’écritures gérés par Unicode, quelle que soit la langue.
5.3.4.1 Expressions régulières Java
Les paramètres de segmentation s’expriment à l’aide d’expressions régulières Java31.
Ces expressions régulières sont documentées :
- dans la documentation de référence Java ;
- ainsi que dans un tutoriel Java, en particulier :
- les classes de caractères ;
- les opérateurs quantificateurs de type « greedy » (gourmand), « reluctant » (réticent) et « possessive » (possessif).
On trouvera un développement complet sur les expressions régulières dans l’ouvrage [friedl_mastering_2002].
5.3.4.2 Segmentation en phrases
Le repérage automatique par défaut des phrases orthographiques de TXM s’appuie sur une simple expression régulière qu’il est possible de modifier en changeant le paramètre Caractères de fin de phrase (le dernier de cette section de paramètres).
Par défaut, ce paramètre a la valeur [.!?]|\.\.|\.\.\.|…|\|], ce qui s’interprète comme le repérage de :
- 1, 2 ou 3 points qui se succèdent
- ou le point d’exclamation
- ou le point d’interrogation
- ou le caractère « points de suspension » (…)
- ou la barre verticale (|)
Attention : le repérage automatique par défaut des phrases orthographiques n’est pas réalisé par tous les modules d’import de TXM. Il n’est pas disponible en particulier pour tous les modules basés sur le format XML depuis TXM 0.7.9, TXM 0.8.0 et TXM 0.8.1.
5.3.4.3 Segmentation en mots
Le repérage automatique par défaut des mots de TXM dépend :
- du repérage d’enclitiques, en fonction de la langue du corpus : français
fr, anglaisenou italienit;
- du repérage d’enclitiques, en fonction de la langue du corpus : français
- du repérage de séparateurs de mots, en fonction de trois paramètres prenant pour valeur des expressions régulières qu’il est possible de modifier :
- Espaces : expression régulière de repérage des espaces.
la valeur par défaut est[\p{Z}\p{C}]+, ce qui s’interprète comme : 1 à n caractères de la catégorie Unicode des « séparateurs » (Z) ou de la catégorie « autres » (C) - Ponctuations : expression régulière de repérage des ponctuations.
la valeur par défaut est[\p{Ps}\p{Pe}\p{Pi}\p{Pf}\p{Po}\p{S}], ce qui s’interprète comme : un caractère de la catégorie Unicode des « ponctuations ouvrantes » (Ps) ou « ponctuations fermantes » (Pe) ou « ponctuations de citation ouvrantes » (Pi) ou « ponctuations de citation fermantes » (Pf) ou « ponctuations autres » (Po) ou « symbole » (S) - Caractères d’élision : expression régulière de repérage des caractères d’élision.
la valeur par défaut est['‘’], ce qui s’interprète comme : un des trois caractères'(apostrophe droite du clavier, « dactylographique » ou guillemet simple),‘(apostrophe tournée) ou’(apostrophe typographique)
Dans la mesure où ces paramètres ont un impact profond sur le repérage des mots, il est recommandé de bien savoir ce que l’on fait quand on modifie ces paramètres.
Le bouton Défaut permet de rétablir les valeurs par défaut de ces paramètres.
Si la segmentation en phrases orthographiques et en mots réalisée par TXM ne conviennent pas, il est toujours
possible de faire réaliser ces segmentations par un autre logiciel, en amont de TXM,
et d’utiliser une représentation XML des textes segmentés pour les importer dans TXM avec
l’un des modules d’import basés sur le format XML, et qui interprètent les balises <s>
pour l’encodage des phrases et <w> pour l’encodage des mots.
Si on ne dispose pas d’outil de segmentation externe, pour des langues comme le chinois il peut être plus avantageux de faire segmenter les mots par caractères au niveau de l’import dans TXM. C’est à dire que chaque « mot » TXM du corpus correspondra à un caractère du texte source. Dans ce cas des expressions CQL de « mot/caractère » ou de séquences de « mots/caractères » permettront de manipuler plus facilement de vrais mots à la demande.
5.3.5 Éditions
Il est possible de contrôler la création des éditions de textes :

Figure 5.9: Paramètre Éditions.
L’option Construire l’édition permet de contrôler la création des éditions de textes.
Il est pratique de ne pas créer systématiquement des éditions pour gagner du temps d’importation. Par exemple quand on teste l’import d’un corpus de grande taille ou que l’on n’a pas encore la version définitive de tous les textes.
L’option Mots par page permet de contrôler la taille des pages d’édition, en particulier pour les modules d’import qui ne disposent pas d’informations sur les sauts de pages au sein des textes (comme les modules basés sur le format texte brut). Si on ne souhaite pas de pagination, il suffit de régler ce paramètre à une grande valeur (supérieure au nombre de mots du texte le plus grand).
5.3.6 Police d’affichage
Il est possible de modifier la police utilisée pour les éditions et pour l’affichage des résultats de TXM :

Figure 5.10: Paramètre Police d’affichage.
Le paramètre Nom de la police permet de choisir une des polices disponibles sur l’ordinateur.
Ce paramètre a été créé pour aider la production d’éditions de textes anciens, qui peuvent nécessiter l’affichage de caractères absents des systèmes d’écritures modernes, et donc des polices de caractères usuelles.
5.4 Paramètres supplémentaires des modules XML
Les modules basés sur le format XML disposent de quelques paramètres généraux supplémentaires.
5.4.1 Segmentation lexicale XML
Le paramètre Balise de mot permet de choisir le nom de la balise XML qui encode les mots (le nom par défaut est w32) :
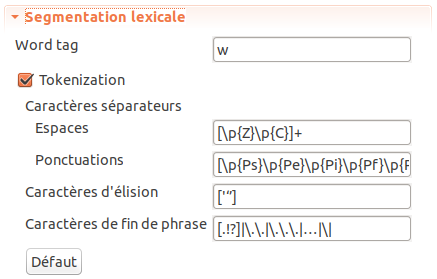
Figure 5.11: Paramètre Segmentation lexicale XML.
Décocher l’option Tokenisation permet d’empêcher le repérage automatique de mots en dehors des balises <w>.
Ceci force TXM à n’utiliser que les mots encodés par des balises <w> (ou d’un autre nom choisi par l’option « Balise de mot »),
ce qui revient à n’utiliser que les mots segmentés par un autre logiciel ou par l’utilisateur.
Si les textes n’encodent pas de mots avec des balises <w> décocher cette option a peu d’utilité, car TXM est peu utile sans mots à exploiter.
5.4.2 Feuille XSL d’entrée
Le module XML/w + CSV permet d’appliquer une feuille de transformation XSL au préalable sur les sources, avant de procéder aux opérations d’importation :
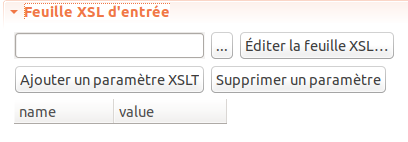
Figure 5.12: Paramètre Feuille XSL d’entrée.
Le bouton […] permet de désigner la feuille XSL à utiliser.
TXM est livré avec une bibliothèque de feuilles XSL à cet effet.
Suivant le système d’exploitation utilisé, le chemin de cette bibliothèque est :
- Sous Windows : « C:\Utilisateurs\<identifiant utilisateur>\TXM-<version>\xsl »
ou bien « C:\Documents and Settings\<identifiant utilisateur>\TXM-<version>\xsl » - Sous Mac OS X : « /Users/<identifiant utilisateur>/TXM-<version>/xsl »
- Sous Linux : « /home/<identifiant utilisateur>/TXM-<version>/xsl ».
La documentation de ces feuilles XSL est partagée en ligne dans le wiki des utilisateurs de TXM.
Le bouton Éditer la feuille XSL… permet d’éditer la feuille de transformation avec l’éditeur de texte intégré de TXM.
Le bouton Ajouter un paramètre XSLT permet d’associer une valeur à un paramètre global de la feuille XSL. Le nom du paramètre et sa valeur sont ajoutés au tableau situé en dessous, ayant pour entêtes « nom » et « valeur ». Ils seront fournis dans le contexte d’appel de la XSL.
Le bouton Supprimer un paramètre permet de supprimer l’association d’une valeur à un paramètre global préalablement ajoutée par « Ajouter un paramètre XSLT ».
5.4.3 Éditions XML
Le paramètre Balise de saut de page permet de choisir le nom de la balise XML qui encode les sauts de page (le nom par défaut est pb33) :
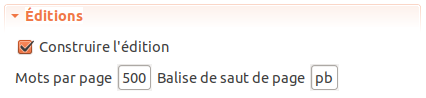
Figure 5.13: Paramètre Éditions XML.
Remarque : le paramètre Mots par page est toujours actif dans les modules basés sur le format XML, donc il est recommandé de régler ce paramètre à une valeur de taille de page théorique haute pour que les balises de sauts de page prennent bien toujours la priorité sur la pagination des éditions.
5.4.4 Paramètres de commandes particulières
Le paramètre Structures délimitant les contextes de concordances permet de choisir les noms des structures internes de textes que les contextes de concordances ne devront pas dépasser, quelle que soit leur taille :

Figure 5.14: Paramètre Commandes.
La valeur par défaut est text34 (soit la structure maximale englobant le contenu de chaque texte d’un corpus), c’est-à-dire que les contextes de concordances ne dépassent pas les limites de textes pour ne pas mélanger le contenu de différents textes dans une même ligne de concordance.
Dans les corpus de transcriptions, par exemple, les structures sp35 peuvent servir à délimiter plus précisément les contextes de concordances pour ne pas mélanger le contenu de tours de paroles différents dans une même ligne de concordance.
Dans ce cas le paramètre prend la valeur « text,sp » pour combiner les limites de ces deux structures.
Attention : ce paramètre prend bien en entrée des noms de structures et non des noms de balises XML, contrairement à d’autres paramètres d’import. Il faut donc bien faire attention à n’utiliser que des noms en minuscules36.
5.5 Enregistrement des paramètres d’import
Jusqu’à TXM 0.7.9, tous les paramètres d’importation étaient sauvegardés automatiquement dans un fichier nommé « import.xml » situé dans le dossier des sources avant d’exécuter le module d’import. À partir de TXM 0.8.0, les paramètres d’importation sont sauvegardés automatiquement dans des fichiers de propriétés du corpus avant d’exécuter le module d’import. [màj080]
Cela permet de relancer l’import d’un même corpus plusieurs fois de suite tout en récupérant le formulaire de paramètres avec les dernières valeurs utilisées.
C’est également une façon de sauvegarder un ensemble de paramètres utilisés pour l’import d’un corpus donné.
5.6 Fichier de métadonnées « metadata »
Les modules nommés ... + CSV peuvent associer à
chaque texte du corpus des métadonnées (propriétés) définies dans un
tableau enregistré dans un fichier annexe situé dans le dossier des sources.
Ce fichier peut être, au choix, dans un des trois formats suivants :
- format tableur LibreOffice
Calc: dans ce cas le fichier doit être nommé « metadata.ods » ; - format tableur MS
Excel: dans ce cas le fichier doit être nommé « metadata.xlsx » ; - format
CSV: dans ce cas le fichier doit être nommé « metadata.csv37 ».
Si un fichier « metadata.ods » ou « metadata.xlsx contient une feuille de calcul nommée « metadata » son contenu sera utilisée, sinon le contenu de la première feuille de calcul du fichier sera utilisée.
Le tableau metadata doit être composé de la façon suivante :
- la première ligne - d’entête - sert à nommer les métadonnées ;
- la première cellule de cette ligne doit obligatoirement contenir la chaîne « id » (en minuscule). Cette cellule définit la colonne de métadonnée « id » qui nommera chaque fichier de texte (sans son extension) ;
- les cellules suivantes de la première ligne définissent les métadonnées supplémentaires.
Elles sont nommées librement, mais doivent respecter
les contraintes suivantes :
- le nom est en minuscules, sans caractères diacritiques
- sans caractère spécial (par exemple :
.,@ç%"#~&) ;
- les lignes suivantes du fichier définissent les valeurs des métadonnées pour chaque texte du corpus, en commençant dans la première colonne par le nom du fichier contenant le texte sans son extension (« .txt », « .xml », « .cnr », etc.) puis en continuant dans les colonnes suivantes avec les valeurs des autres métadonnées.
Les tableaux des versions tableurs peuvent utiliser des mises en forme, des styles et des couleurs pour aider la lecture du tableau. Ils ne seront pas interprétés par TXM.
5.6.1 Exemple de fichier « metadata » du corpus VOEUX
Voici les trois premières lignes du fichier de métadonnées du corpus exemple VOEUX « metadata.ods » :
| id | loc | annee |
| 0001 | dg | 1959 |
| 0002 | dg | 1960 |
| 0003 | dg | 1961 |
Glose :
- la colonne « id » encode les identifiants de textes (métadonnée obligatoire) :
comme le corpus VOEUX est importé par le module
TXT + CSV, pour que la relation entre les métadonnées (définies dans le fichier « metadata.ods ») et les textes (définis dans le dossier des sources du corpus) puisse s’établir, il faut que les trois premiers textes du corpus soient représentés dans le dossier des sources respectivement par des fichiers nommés « 0001.txt », « 0002.txt » et « 0003.txt ». - la colonne « loc » (métadonnée supplémentaire, utile aux études faites sur le corpus) encode le nom du président qui prononce le discours (code « dg » pour « De Gaulle »38)
- la colonne « annee39 » (métadonnée supplémentaire, utile aux études faites sur le corpus) encode l’année où le discours a été prononcé.
Pour encoder les mêmes lignes, un fichier « metadata.csv » prendrait la forme suivante :
id,loc,annee
0001,dg,1959
0002,dg,1960
0003,dg,1961Important : à partir de TXM 0.8.0, il est recommandé de toujours utiliser le format LibreOffice Calc pour le fichier « metadata » des corpus, soit un fichier nommé « metadata.ods ». La gestion du format CSV par les tableurs est beaucoup moins fiable entre les systèmes d’exploitation et entre les versions d’un même système d’exploitation (par exemple entre la version anglaise et la version française).
5.6.2 Prévisualisation des métadonnées dans le formulaire de paramètres d’import
Quand un fichier « metadata » est présent dans le dossier des sources, le formulaire d’import permet de prévisualiser son contenu avec l’onglet « Aperçu des métadonnées » situé en bas à gauche du formulaire :

Figure 5.15: Onglet d’aperçu des métadonnées.
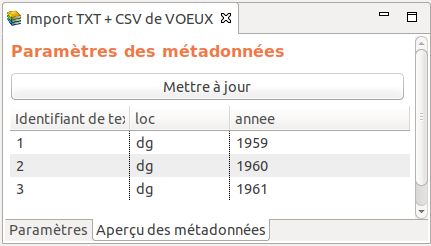
Figure 5.16: Aperçu des métadonnées du fichier « metadata.ods » du corpus VOEUX.
5.6.3 Mise en œuvre du fichier « metadata »
La présence d’un tableau « metadata » dans le dossier de sources n’est pas obligatoire, ou son contenu peut n’être que partiel, pour pouvoir réaliser un import.
Cela permet de commencer à tester et à exploiter un corpus sans avoir encore réuni toutes les informations sur les textes,
ou plus simplement pour une étude n’a pas besoin de s’appuyer sur des propriétés de textes.
Dans le même ordre d’idées, un tableau « metadata » peut contenir des lignes renseignant des textes qui ne sont pas (encore) présents dans le dossier de sources.
Cela permet de travailler sur la documentation des textes d’un corpus en parallèle avec la préparation des textes sources40.
Le corpus ne contiendra que les textes dont les fichiers source sont présents au moment de l’import.
Il faudra ré-importer le corpus au fur et à mesure de la disponibilité de nouveaux fichiers textes dans le dossier de sources.
5.7 Noms des fichiers source
Les noms des fichiers source sont utilisés pour construire l’identifiant unique de chaque texte d’un corpus, puis pour faire la relation entre un texte et ses métadonnées. Comme la gestion des noms de fichiers est variable selon les systèmes d’exploitation, il est recommandé de limiter l’usage de caractères non alphanumériques :
- ne pas utiliser de point (.), comme dans ‘p.’, dans les noms de fichiers ;
- ne pas utiliser l’espace ( ), comme dans ‘p. 9’, dans les noms de fichiers ;
- ne pas utiliser de caractères à diacritiques (accent, cédille), comme dans ‘français’, dans les noms de fichiers.
5.8 Lancement d’un module d’import
Une fois les paramètres d’import renseignés dans le formulaire et les textes source prêts, on lance l’import en cliquant sur le bouton vert avec la flèche ou en cliquant sur le lien hypertexte « Lancer l’import du corpus » :

Figure 5.17: Lancement de l’import.
Le résultat est un nouveau corpus ajouté à la vue « Corpus » auquel on peut appliquer toutes les commandes de TXM : Propriétés, Lexique, Concordances, Édition, etc.
5.9 Modules d’importation de textes écrits
5.9.1 Module Presse-papier : import depuis le presse-papier du système d’exploitation
L’import Presse-papier est la façon la plus simple et la plus rapide, mais aussi la plus limitée, de créer un corpus dans TXM.
5.9.1.1 Entrée
Ce module importe le contenu du presse-papier du système, interprété comme du texte brut.
5.9.1.2 Sortie
En sortie, on obtient une structure de texte (text) unique et des mots segmentés automatiquement.
Chaque mot reçoit une propriété « lb » encodant le numéro de la ligne sur laquelle il se trouve dans le texte brut source.
5.9.1.3 Annotation
Si l’extension TreeTagger est installée, les mots sont également catégorisés et lemmatisés selon la langue choisie dans la préférence « TXM / Utilisateur / Import / Clipboard / Default language ».
5.9.1.4 Édition
Une édition de texte brut est construite : - en appliquant les règles typographiques d’espaces et de ponctuations entre les mots selon la langue41 ; - en paginant par blocs de 500 mots.
5.9.2 Module TXT+CSV : import de fichiers de texte brut (.txt)
5.9.2.1 Entrée
Corps de texte
Ce module importe un dossier de fichiers contenant du texte tout venant (format texte brut). L’extension des fichiers doit être ‘.txt’.
Les sauts de ligne (du texte brut) sont interprétés et chaque mot encode son numéro de ligne dans la propriété « lb ».
Métadonnées de texte
Les métadonnées des textes sont encodées dans le fichier « metadata » situé dans le même dossier que les fichiers sources, voir la section 5.6 page ??.
5.9.3 Module ODT/DOC/RTF+CSV : import de documents de traitements de texte (.docx, .odt…)
Avertissement
L’utilisation de ce module nécessite l’installation préalable sur la machine de Libre Office version 4 ou supérieure.5.9.3.1 Entrée
Corps de texte
Ce module importe un dossier de fichiers au format « traitement de texte » :
.docx, .doc : MS Word ;
.odt : Libre Office Writer
.rtf
etc.
Tous les formats suportés par Libre Office Writer sont importables avec ce module[29].
Métadonnées de texte
Les métadonnées des textes sont encodées dans l fichier « metadata » situé dans le même dossier que les fichiers sources.
Le séparateur de colonnes est « , ». Le caractère de champ est « “ ».
La première colonne doit être nommée « id », les suivantes sont nommées à la discrétion de l’utilisateur mais sans utiliser de caractères accentués ou spéciaux.
La première colonne doit contenir le nom du fichier source (sans extension) qui correspond aux métadonnées de la ligne.
5.9.3.2 Sortie
En sortie, on obtient des textes (text) ayant des propriétés correspondant aux métadonnées et contenant les paragraphes des documents source.
5.9.3.4 Édition
Il y a une édition par texte paginée selon les sauts de page manuels insérés dans les documents ainsi que selon la pagination automatique des traitements de texte.
La première page d’édition de chaque texte reprend la liste des métadonnées.
Les styles de caractères et les styles de paragraphes sont transférés dans les éditions.
Les titres de sections sont encodés dans des titres de section HTML (<h2>).
Les illustrations sont transférées dans les éditions si un dossier nommé « images » contenant toutes les images est copié manuellement dans le dossier « HTML » des éditions. Sont également transférés dans les éditions :
les tableaux ;
les listes à puces ;
les mises en italiques et en gras.
5.9.4 Module XML/w+CSV : import de fichiers en format XML tout venant (.xml)
5.9.4.1 Entrée
5.9.4.1.1 Corps de texte
Ce module importe un dossier de fichiers[30] contenant du texte au format XML (Bray, Paoli, Sperberg-McQueen, Maler, & Yergeau, 2008b). L’extension de fichier correspondante est ‘.xml’ par défaut.
Chaque balise XML encode un niveau de structure avec ses propriétés. Le nom de la structure vient du nom de la balise et les propriétés et leur valeur viennent des attributs et de leur valeur. La balise « text » est réservée pour ce module.
Si des mots sont délimités par des balises « <w> » portant des attributs, ils sont interprétés en tant que tels, sauf l’attribut « id » qui est réservé pour TXM (les sources ne doivent pas utiliser cet attribut). Il faut toutefois faire attention à ce que tous les <w> aient les mêmes noms d’attributs. Si les balises <w> possèdent un attribut « ref », alors celui-ci sera utilisé pour afficher les références par défaut des concordances.
Avertissement concernant tous les modules basés sur le format XML
Tous les éléments XML et leurs attributs sont importés dans TXM sous la forme de structures avec propriétés et de mots avec propriétés par le moteur de recherche CQP. Comme la syntaxe du langage de requêtes (CQL) de ce dernier utilise des mots-clés réservés, il n’est pas possible d’utiliser des noms de structures et de propriétés correspondant à ces mots-clés. La liste des mots que l’on ne peut pas utiliser pour nommer une structure ou une propriété, et donc pour nommer un élément ou un attribut XML, est la suivante : asc, ascending, by, cat, cd, collocate, contains, cut, def, define, delete, desc, descending, diff, difference, discard, dump, exclusive, exit, expand, farthest, foreach, group, host, inclusive, info, inter, intersect, intersection, join, keyword, left, leftmost, macro, maximal, match, matchend, matches, meet, MU, nearest, no, not, NULL, off, on, randomize, reduce, RE, reverse, right, rightmost, save, set, show, size, sleep, sort, source, subset, TAB, tabulate, target, target[0-9], to, undump, union, unlock, user, where, with, within, without, yes ;
La gestion de la récursion des structures par CQP peut interférer avec des suffixes de numérotation de noms d’éléments et d’attributs. Par exemple quand trois éléments ‘<div>’ sont imbriqués, l’indexation CQP les recodera sous les noms (non récursifs) ‘div, div1, div2’. Il vaut donc mieux éviter de nommer les éléments et attributs XML avec des suffixes numériques ;
Le caractère underscore (_) étant réservé dans le langage de requêtes CQL, il ne peut pas être utilisé dans les noms de structures et de propriétés donc d’éléments et attributs XML.
Identifiants de textes : la propriété « id » des textes est construite à partir des noms de fichiers source (en retirant l’extension « .xml »). La valeur de cette propriété doit être conforme à celle d’un identifiant CSS (pas d’espace, etc.). Si les textes des sources possèdent un attribut « id » il faut le déplacer dans un autre attribut avant ou pendant l’import.
Identifiants de mots : la propriété « id » des mots, utilisée pour le retour au texte, etc., provient de l’attribut « xml:id » des éléments « <w> ». La valeur de cet attribut doit avoir la syntaxe « w_<identifiant de texte[31]>_<numéro du mot dans le texte[32]> ». Cette information est créée par les modules d’import si elle ne se trouve pas dans les mots. Si les mots des sources possèdent un attribut « id » il faut le déplacer dans un autre attribut avant ou pendant l’import.
5.9.4.1.2 Métadonnées de texte
Les métadonnées des textes sont encodées dans le fichier « metadata » situé dans le même dossier que les fichiers sources.
Le séparateur de colonnes est « , ». Le caractère de champ est « “ ».
5.9.4.1.3 Paramètres supplémentaires
Un fichier «import.properties » situé dans le dossier des sources permet de régler les paramètres suivants :
stopifmalformed : interrompt l’import si un des fichier XML est mal formé.
ignoredelements : expression régulière des noms de balises que le tokenizeur doit ignorer (le « hors-texte »). Par exemple : “note|teiHeader”
normalizemetadata : normaliser les valeurs des propriétés de structures = true/false. Les valeurs de métadonnée de texte seront passées en minuscules.
sortmetadata : nom de la métadonnée utilisée pour définir l’ordre entre les textes
Exemple de fichier « import.properties » :
stopifmalformed =false
ignoredelements =note|teiHeader
normalizemetadata=true
sortmetadata=true
5.9.4.1.4 Prétraitements XSL front
Le module d’import XML/w permet d’appliquer une feuille de transformation XSL à l’ensemble des sources avant tout traitement par le module d’import. Ces traitements permettent d’adapter à la volée le format des sources aux besoins du module d’import de TXM.
TXM est livré avec une bibliothèque de feuilles XSL utiles à ces prétraitements.
Feuilles d’adaptation de sources au format XML-TEI P5
- txm-filter-teip5-xmlw-preserve.xsl : rend compatible n’importe
quel document au format XML-TEI P5 pour un import dans TXM. Par
défaut, elle supprime le contenu des éléments <teiHeader> et
<facsimile> et laisse tous les autres éléments inchangés.
Il est possible d’appliquer cette feuille de style indépendamment du module d’import XML/w+CSV, par exemple avec l’aide de la macro ExecXSL, avec les paramètres suivants :- deleteAll : liste des noms de balises à supprimer avec leur contenu, les noms sont séparés pas des barres verticales (« teiHeader|facsimile » par défaut)
- deleteTag : liste des noms de balises à supprimer en conservant leur contenu, les noms sont séparés pas des barres verticales (liste vide par défaut)
- txm-filter-teip5-xmlw-simplify.xsl : rend compatible n’importe
quel document au format XML-TEI P5 pour un import dans TXM en ne
gardant que les balises <ab>, <body>, <div>, <front>,
<lb>, <p>, <pb>, <s>, <TEI>, <text> et <w> dans le
corps du texte.
Il est possible d’appliquer cette feuille de style indépendamment du module d’import XML/w+CSV, par exemple avec l’aide de la macro ExecXSL, avec les paramètres suivants :deleteAll : liste des balises à supprimer avec leur contenu, les noms des balises sont séparés pas des barres verticales (« teiHeader|facsimile » par défaut)
copyAll : liste des balises à conserver, les noms des balises sont séparés pas des barres verticales (« ab|body|div|front|head|lb|p|pb|s|TEI|text|w » par défaut) ;
Toutes les autres balises sont supprimées, leur contenu textuel est en revanche conservé.
- txm-filter-bnc_oral-xmlw.xsl : adapte les transcriptions de
l’oral du
BNC
pour un traitement dans TXM.
- Projette dans des attributs de balise
<div>le contenu de certaines métadonnées du teiHeader (pour faciliter les contrastes internes entre types d’activités) :titleStmt/titleprofileDesc/creationclassCode[@scheme='DLEE']setting/placeNamesetting/localesetting/activitysetting/activity/@spontrecording/@date ou profileDesc/creation
- Projette dans des attributs de la balise <u> le contenu de
certaines métadonnées du teiHeader (pour faciliter les
contrastes internes entre types de locuteurs) :
profileDesc/particDesc/person[…]/@*
- Projette dans des attributs de balise
Feuilles d’adaptation de sources de corpus particuliers
- txm-filter-corpusakkadien-xmlw_syllabes-cuneiform.xsl : filtre de choix des unités lexicales au niveau des syllabes ou au niveau des mots du corpus de tablettes cunéiformes en Akkadien ;
- txm-filter-perseustreebank-xmlw.xsl : filtre d’adaptation des textes du projet Perseus Treebank ;
- txm-filter-qgraal_cm-xmlw.xsl : filtre d’adaptation du format diffracté de la Quête du Graal ;
- txm-filter-rnc-xmlw.xsl : filtre d’adaptation des textes du corpus National Russe ;
- txm-filter-teibrown-xmlw.xsl : filtre d’adaptation des textes du corpus BROWN du projet NLTK/Brown ;
- txm-filter-teibvh-xmlw.xsl : filtre d’adaptation des textes TEI du corpus BVH ;
- txm-filter-teicorpustextgrid-xmlw.xsl : filtre d’adaptation des textes TEI du corpus TextGrid de DARIAH-DE ;
- txm-filter-teifrantext-xmlw.xsl : filtre d’adaptation des textes du corpus Frantext libre.
- txm-filter-teiperseus-xmlw.xsl : filtre d’adaptation des textes TEI du projet Perseus après conversion en TEI P5.
5.9.4.2 Édition
Il y a une édition par texte, paginée par défaut par blocs de n mots.
5.9.4.2.1 Interprétation des éléments XML pour construire l’édition
Ce module d’import interprète certains éléments XML pour mettre en forme les éditions (HTML) :
Élément text
produit un titre h3 avec l’identifiant du texte (le contenu de l’attribut
@id) au début de la première page de l’éditionsuivi d’un tableau des noms et valeurs des métadonnées du texte
un saut de ligne est forcé après le tableau
Élément head
- produit un titre h2 avec le contenu de l’élément
Élément note
produit un appel de note avec un span contenant le texte « [*] » en rouge affichant un tooltip composé du contenu des sous-éléments w/form et du texte hors w
par défaut, le contenu des notes (le contenu du tooltip) est segmenté et indexé par le moteur de recherche (mais le retour au texte est impossible à partir de concordances). Pour que le contenu des notes ne soit pas indexé, il faut ajouter l’élément note au paramètre d’import ignoredelements.
Élément graphic
- produit un élément div contenant un élément img ayant l’attribut
@srcà la valeur de l’attribut@urlde l’élément graphic et l’attribut@alignà la valeur ‘middle’. Si l’attribut@urln’est pas renseigné, cet élément est ignoré.
- produit un élément div contenant un élément img ayant l’attribut
Éléments lg, p et q
- produit un paragraphe p ayant l’attribut CSS
@classà la valeur de l’attribut@rendde l’élément d’origine. Si l’élément d’origine n’a pas d’attribut@rendrenseigné, le paragraphe n’a pas de style particulier.
- produit un paragraphe p ayant l’attribut CSS
Éléments lb et br
- force un saut de ligne br
Élément pb (ou la balise de pagination indiqué par le paramètre d’import editionpage)
clos la page courante et ouvre une nouvelle page de l’édition. Si cet élément apparaît au sein d’une imbrication d’éléments, ces derniers sont refermés avant de clore la page courante puis ré-ouverts au début de la nouvelle page.
numérote la nouvelle page par un paragraphe p centré en haut de la page. Le numéro de page de format « - n - » est affiché en rouge à partir du contenu de l’attribut
@nde l’élément pb. Si l’élément pb n’a pas d’attribut@non affiche un numéro de page automatique incrémenté à partir de 1.
5.9.4.2.2 Stylage par CSS
Il est possible de personnaliser le stylage des pages HTML par CSS de deux façons différentes.
- fichier CSS du corpus : on peut déposer un fichier nommé « MONCORPUS.css » dans le dossier de l’édition par défaut du corpus $TXMHOME/corpora/MONCORPUS/html/default.
Cette CSS est déclarée dans chaque page HTML par la déclaration suivante :
<link rel="stylesheet" type="text/css" href="MONCORPUS.css"/>
Cette feuille de style CSS définit globalement le style de chaque élément HTML ou bien des classes qui seront associées aux différents types de lg, p et q.
- fichier CSS de TXM : on peut modifier la feuille de style par défaut de TXM $TXMHOME/css/txm.css. Cette CSS est déclarée dans chaque page HTML par la déclaration suivante :
<link rel="stylesheet" type="text/css" href="txm.css"/>
Attention : la modification de ce fichier impactera le style de toutes les éditions produites ultérieurement par les modules d’import de TXM.
5.9.5 Module XML-TEI Zero+CSV (dit aussi XTZ+CSV ou XTZ) : import de XML TEI générique (.xml)
Le module XTZ est capable d’interpréter de façon progressive un jeu minimal de balises TEI appelé « TEI Zero » (dans la lignée des jeux de balises TEI minimaux déjà existants TEI lite, TEI tite, TEI bare ou TEI Simple). Les balises interprétées servent à construire les données habituellement exploitées par TXM dans l’indexation des mots, dans la construction des éditions, etc. Cet import est progressif au sens où il n’est pas nécessaire d’encoder toutes les balises du jeu disponible dans un corpus donné pour pouvoir être importé par le module. l’utilisateur n’encode que les balises qui lui sont nécessaires dans l’exploitation avec TXM.
Ce module remplace le module XML/w+CSV comme module interprétant des balises a priori et de façon progressive, et il s’utilise dans le même esprit.
Ce module est recommandé pour l’import progressif de textes tout-venant encodés en XML-TEI.
5.9.5.1 Balises TEI interprétées
5.9.5.1.1 Unités textuelles
Élément <text>
<text>encode les unités textuelles (les textes) ;- les attributs
text@MMprésents deviennent des métadonnées ; - ces métadonnées sont fusionnées avec celles du fichier metadata ;
- cette balise est la seule balise obligatoire.
5.9.5.1.2 Unités lexicales
Éléments <w>
<w>pré-encode certains ou tous les mots ;- les attributs
w@PPdeviennent des propriétés de mots ; - l’attribut
@xml:idest réservé pour TXM (les sources ne doivent pas utiliser l’attribut id).
5.9.5.1.3 Autres éléments
Tous les autres éléments XML (les autres balises) sont transférés tels
quels comme structures intermédiaires entre l’unité textuelle et les
unités lexicales, leurs attributs devenant les propriétés des
structures. Ces éléments ne sont pas disponibles dans les éditions par
défaut, produites par le module. En revanche, ils peuvent être
conservés dans les éditions (sous la forme d’éléments HTML <span> avec
l’attribut @class, par exemple) dans les éditions produites par des
feuilles de style XSLT (voir plus bas).
Avertissements
Tous les éléments XML et leurs attributs sont importés dans TXM sous la forme de structures avec propriétés et de mots avec propriétés par le moteur de recherche CQP. Comme la syntaxe du langage de requêtes (CQL) de ce dernier utilise des mots-clés réservés, il n’est pas possible d’utiliser des noms de structures et de propriétés correspondant à ces mots-clés. La liste des mots que l’on ne peut pas utiliser pour nommer une structure ou une propriété, et donc pour nommer un élément ou un attribut XML, est la suivante :
asc,ascending,by,cat,cd,collocate,contains,cut,def,define,delete,desc,descending,diff,difference,discard,dump,exclusive,exit,expand,farthest,foreach,group,host,inclusive,info,inter,intersect,intersection,join,keyword,left,leftmost,macro,maximal,match,matchend,matches,meet,MU,nearest,no,not,NULL,off,on,randomize,reduce,RE,reverse,right,rightmost,save,set,show,size,sleep,sort,source,subset,TAB,tabulate,target,target[0-9],to,undump,union,unlock,user,where,with,within,without,yes;La gestion de la récursion des structures par CQP peut interférer avec des suffixes de numérotation de noms d’éléments et d’attributs. Par exemple quand trois éléments
<div>sont imbriqués, l’indexation CQP les recodera sous les noms (non récursifs) ‘<div>,<div1>,<div2>’. Il vaut donc mieux éviter de nommer les éléments et attributs XML avec des suffixes numériques ;Le caractère underscore (
_) étant réservé dans le langage de requêtes CQL, il ne peut pas être utilisé dans les noms de structures et de propriétés donc d’éléments et attributs XML.
5.9.5.2 Éditions
Toutes les pages d’édition sont encodés en HTML5 + CSS3 + Javascript.
5.9.5.2.1 Production de l’édition par défaut
Page de garde
L’édition possède une page de garde contenant :
- un titre
<h3>composé de l’identifiant du texte (la valeur de<text@id>) ; - le tableau des métadonnées (la valeur de
<text@id>).
Intertitres
<head>crée un élément<h2>;- si
head@rendest présent il est transféré dansh2@rend.
Paragraphes
<p>crée un paragraphe<p>;- si
p@rendest présent il est transféré dansp@rend.
Mises en évidence
<hi>rend le texte en gras<b>;- si
hi@rend='i|italic',hiest converti eni; - si
hi@rend='b|bold',hiest converti enb; <emph>rend le texte en italique<i>;- si
emph@rend='i|italic',emphest converti eni; - si
emph@rend='b|bold',emphest converti enb.
Sauts de ligne
<lb>crée un saut de ligne forcé (élément<br>) ;
Listes à puces
<list>crée une nouvelle liste à puces :- si
list@type= unordered → liste à puces<ul>; - si
list@type= ordered → liste numérotée<ol>.
- si
- si
list@rendest présent il est transféré dansul@rendouol@rend; <item>crée une nouvelle entrée<li>;- si
item@rendest présent il est transféré dansli@rend.
Tableaux
<table>crée un nouveau tableau HTML<table>;- si
table@rendest présent il est transféré danstable@rend; <row>crée une nouvelle ligne<tr>;- si
row@rendest présent il est transféré danstr@rend; <cell>crée une nouvelle cellule<td>;- si
cell@rendest présent il est transféré danstd@rend;
Illustrations
<graphic>insère une image (élément HTML<img>avecimg@align="middle"- l’image est centrée -, inséré dans une<div>) ;- si
graphic@urlest présent il est transféré dansimg@src.
Liens hypertextes
<ref>insère un lien hypertexte<a>aveca@target="_blank"(le lien s’ouvre dans un nouvel onglet) ;- si
ref@targetest présent il est transféré dansa@href.
Notes de bas de page
<note>insère :- un appel de note
<a>numéroté à partir de 1 dans la page aveca@id="noteref_N",a@title="contenu de la note"eta@href="note_N"; - une note de bas de page composée :
- d’un lien retour vers l’appel
a@id="note_N"eta@href="noteref_N"; - du contenu de la note dans un
<span>.
- d’un lien retour vers l’appel
- un appel de note
Pagination
- l’élément de pagination termine la page courante en fermant les listes, paragraphes, sections, etc. ouverts ;
- par défaut l’élément de pagination est
<pb>(valeur du paramètre « pageBreakTag ») ; - si un attribut
pb@facsest renseigné et la construction de l’édition synoptique est demandée (paramètre “Build ‘facs’ edition”), alors l’URL est utilisée pour accéder à l’image de la page pour construire l’édition facsimilé ; - si on n’utilise pas d’éléments de pagination, cette dernière est réalisée en nombre de mots par page (paramètre “Mots par page”) ;
- crée une nouvelle page en ré-ouvrant si nécessaire certains éléments au préalable (listes, etc.) ;
- numérote la page dans l’entête avec un paragraphe centré de
contenu ”
- p@n -” de couleur rouge.
Mots
<w>génère un mot inséré dans un élément HTML<span>ayant un attributspan@xml:idunique et unspan@titlecontenant la liste de toutes ses propriétés.
Stylage par CSS
Il est possible de personnaliser le stylage des pages HTML par CSS de trois façons différentes.
- dossier de CSS du corpus : on peut créer un dossier « css » dans le dossier des sources et y déposer des feuilles CSS (d’extension « .css »). Le dossier « css » et les feuilles qu’il contient seront copiés dans le dossier de l’édition par défaut du corpus $TXMHOME/corpora/MONCORPUS/html/default. Il suffit alors de déclarer les CSS dans le HTML produit pour l’édition, par exemple :
<link rel="stylesheet" type="text/css" href="MyCSS.css">
- fichier CSS du corpus : on peut déposer un fichier nommé
«
MONCORPUS.css» dans le dossier de l’édition par défaut du corpus$TXMHOME/corpora/MONCORPUS/html/default.
Cette CSS est déclarée dans chaque page HTML par la déclaration suivante :
<link rel="stylesheet" type="text/css" href="MONCORPUS.css">
Cette feuille de style CSS définit globalement le style de chaque élément HTML ou bien des classes qui seront associées aux différents types de lg, p et q.
- fichier CSS de TXM : on peut modifier la feuille de style par défaut
de TXM
$TXMHOME/css/txm.css. Cette CSS est déclarée dans chaque page HTML par la déclaration suivante :
<link rel="stylesheet" type="text/css" href="MONCORPUS.css">
Attention : la modification de ce fichier impactera le style de toutes les éditions produites ultérieurement par les modules d’import de TXM.
Images et Javascript
Les images et les scripts Javascript utilisés par les pages HTML
d’édition peuvent être fournis à l’édition par le biais de dossiers
« images », respectivement « js », situés dans le dossier des
sources. Si ces dossiers sont présents dans les sources leur contenu
est transféré dans le dossier de l’édition par défaut
$TXMHOME/corpora/MONCORPUS/html/default. Le HTML peut alors y accéder
par des URL relatives de la forme « images/image1.jpg ».
5.9.5.2.2 Production de l’édition “fac-similé”
Le module XTZ peut produire des éditions synoptiques affichant côte-à-côte différentes versions de chaque page :
- l’image du facsimilé de la page (son scan ou sa photo) ;
- l’édition critique de la page ;
- une autre édition de la page ;
- une traduction de la page ;
- etc.
Par défaut, seule une édition simple, non synoptique, est produite à l’import.
Le module construit une édition incluant les images de pages (de fac-similé) quand on coche l’option « Construire l’édition fac-similé/Build ‘facs’ edition » du formulaire de paramètres d’import. L’édition des textes est alors implicitement synoptique en combinant au moins l’édition du texte de base et l’édition fac-similé.
Les sources doivent contenir des éléments XML de saut de page, dont on
peut choisir le nom avec le paramètre « Balise de saut de page » (valeur « pb » par défaut).
Les images des pages peuvent se trouver sur la machine de l’utilisateur (locales) ou bien être accessibles depuis Internet (distantes).
Désignation d’images de pages locales à partir de fichiers
- Si les sources ne contiennent pas d’attribut
@facsencodant l’adresse des images dans l’élément de pagination, TXM peut créer ces adresses au moment de la pagination. Il faut alors organiser le dossier d’images de la façon suivante :
- toutes les images des pages d’un texte donné doivent être regroupées dans un dossier ayant comme nom l’identifiant du texte ;
- tous les dossiers d’images de pages de textes doivent être regroupés dans un dossier de base des images du corpus.
Quand le chemin vers ce dossier de base est fournit au paramètre
« dossier d’images/Images directory », le module d’import ajoute
ou modifie les attributs @facs de tous les éléments de saut de page du
corpus à partir des noms de fichiers images. l’ordre alphabétique des
noms de fichiers images sera utilisé pour correspondre à l’ordre des
sauts de page au fil du texte. Les dossiers d’images sont recopiés
dans le corpus binaire.
- Si les sources contiennent un attribut
@facsencodant l’adresse fichier des images dans l’élément de pagination, il suffit de déposer les dossiers d’images de fac-similés dans le dossier «images» des sources pour qu’ils soient copiées au moment de l’import et pointés depuis les éditions. Dans ce cas il n’est pas nécessaire de renseigner le paramètre « dossier d’images/Images directory ».
Désignation d’images distantes par encodage d’URLs dans les sources
Si le paramètre « dossier d’images/Images directory » est laissé
vide, le module d’import va interpréter directement les valeurs des
attributs @facs de chaque élément de saut de page.
Ces valeurs doivent être des URLs absolues ou relatives, distantes (avec
le préfixe « http:// », pour désigner une image sur un serveur web) ou
locales (avec le préfixe « file:// », c’est à dire désignant des
fichiers se trouvant sur la machine de l’utilisateur). Les URLs ne sont
pas vérifiées au moment de l’import. Il faut s’assurer de la
disponibilité de l’accès aux images au moment de l’exploitation du
corpus.
5.9.5.2.3 Production d’éditions par XSL
Le module XTZ+CSV produit des éditions par défaut en interprétant certains éléments TEI.
L’étape d’import « 4-edition » permet de produire des éditions supplémentaires à l’aide de feuilles de transformation XSL s’appliquant aux représentations XML-TEI TXM de chaque texte du corpus (voir la section 5.2.1.5.4 page 69).
Une édition est produite par deux XSL appliquées successivement :
- une première nommée «
<n° ordre>-<nom de l’édition>-html.xsl» qui produit un fichier HTML à partir d’un fichier XML-TEI TXM ; - une seconde nommée «
<n° ordre+1>-<nom de l’édition>-pager.xsl» qui pagine l’édition en découpant le fichier HTML initial en autant de fichiers HTML que de pages.
L’édition est stockée dans le sous-dossier « <nom de l’édition> »
du dossier « HTML » du corpus binaire. Le nom de l’édition ne doit
pas contenir de tiret « - ».
Le nom de l’édition apparaîtra dans le menu des éditions disponibles de l’Édition du corpus.
Si on utilise le nom d’édition « default », l’édition par défaut sera
remplacée par celle construite par XSL.
5.9.5.3 Plans textuels
Le module XTZ peut ignorer certaines balises ou certains contenus de balises lors de l’indexation pour le moteur de recherche ou lors de la production des pages d’édition.
5.9.5.3.1 Hors texte
Ces éléments sont supprimés entièrement en amont de l’étape de tokénisation. Ils ne sont pas disponibles pour la production des éditions, ni pour la création de références.
5.9.5.3.2 Hors texte à éditer
Ces éléments sont conservés, mais le texte qu’ils contiennent n’est pas tokénisé et indexé par le moteur de recherche. En revanche, ce texte est affiché dans les éditions. Exemples d’usage : Introduction à une édition scientifique, titres ajoutés par l’éditeur, entêtes TEI dont on veut utiliser des métadonnées.
5.9.5.3.3 Notes
Un type particulier de hors texte à éditer qui prend la forme de notes de bas de page dans les éditions par défaut.
5.9.5.3.4 Milestones
Le moteur de recherche CQP utilisé par TXM ne peut pas prendre en compte les éléments ou balises vides (milestone) XML[33]. Cette option permet de déplacer l’information d’éléments milestone dans les propriétés de mots voisins pour pouvoir exprimer des contraintes d’extraction basée sur ces informations. Pour chaque balise milestone indiquée dans ce paramètre (les noms de balises sont séparés par une virgule), on ajoute aux mots entourant ces balises les propriétés suivantes :
<nom élément milestone>id: l’identifiant (xml:id) du milestone précédent le mot<nom élément milestone>start: la distance en mots au milestone précédent le mot<nom élément milestone>end: la distance en mots au milestone suivant le mot
Par exemple, avec la valeur de paramètre : « lb,cb,pb42 », on ajoute à
tous les mots les propriétés suivantes :
lbid,lbstartetlbend;cbid,cbstartetcbend;pbid,pbstartetpbend.
Ces propriétés permettent d’exprimer des contraintes comme
« [int(pbstart) = 0] » pour désigner tous les premiers mots de
pages, ou encore « [int(lbend) = 0] » pour désigner tous les mots
situés en fin de ligne.
Remarque : on peut également utiliser dans le paramètre Milestone des éléments qui ne sont pas des éléments milestone XML. Cela permet d’exprimer des contraintes de distance basées sur ces structures également.
5.9.5.4 Traitements XSL intermédiaires à certaines étapes clés du traitement du module
Le module XTZ permet d’appliquer des XSL aux sources en cours de traitement lors de 4 étapes clés :
- 1-split-merge : traitement initial permettant de changer l’architecture des fichiers, par exemple pour la rendre conforme au modèle de corpus de TXM 1 fichier = 1 texte ;
- 2-front : prétraitement pour changer le contenu des fichiers,
par exemple pour éliminer (eg
teiHeader) ou transformer certains éléments ; - 3-posttok : traitement final de la version tokenisée de chaque
texte où chaque mot est encodé par un élément «
w» avec des attributs encodant ses propriétés, par exemple pour recomposer les mots césurés du corpus ; - 4-edition : production d’éditions HTML à partir de la version XML-TEI TXM[34] pivot de chaque texte et de la pagination réalisée par le composant de création d’édition par défaut (le Pager).
À chacune de ces étapes clés correspond un dossier de même nom contenant les XSL des traitements à appliquer à cette étape clé. Les XSL sont appliquées dans l’ordre lexicographique de leur nom. Les dossiers de traitements XSL intermédiaires sont regroupés dans un dossier « xsl » situé lui-même dans le dossier des sources. Les traitements sont déclenchés en fonction de la présence des ces dossiers et des XSL.
Chaque XSL reçoit les paramètres suivants :
number-words-per-page: le nombre de mots par page si indiqué dans le formulaire d’import ;pagination-element: l’élément XML à utiliser pour les sauts de page si indiqué dans le formulaire d’import ;import-xml-path: le chemin du fichier de stockage des paramètres d’import dans le dossier source.
Cas des XSL de production de l’édition HTML (point ‘4-edition’) :
- elles reçoivent un paramètre supplémentaire ‘output-directory’ qui est le chemin du dossier de sortie des résultats ;
- elles doivent produire un élément
<meta name="description" content="{id du 1er mot de la page}"/>dans l’entête de chaque page produite. Si la page ne contient pas de mot (eg page de garde), elle doivent produire un élément<meta name="description" content="w_0"/>dans l’entête de la page.
Les DTD ou schémas utilisés par les XSL doivent être fournis dans le dossier ‘dtd’ du dossier des sources.
5.9.5.4.1 Bibliothèque de feuilles XSL de transformation intermédiaire
TXM est livré avec une librairie de feuilles XSL utiles aux traitements intermédiaires. Les versions les plus à jour de ces XSL se trouvent en ligne à l’adresse https://txm.gitpages.huma-num.fr/textometrie/files/library/xsl.
1-split-merge
- txm-rename-files-no-dots.xsl : remplace les points (.) dans les
noms de fichiers source par un souligné (
_). Utile pour contourner le bug sur les noms de fichiers source ; - txm-split-teicorpus.xsl : éclate en plusieurs fichiers un fichier source contenant un élément teiCorpus composé de plusieurs éléments TEI. Utile pour obtenir une unité textuelle et une édition par texte du corpus TEI dans TXM ;
2-front
Traitements génériques
- filter-keep-only-select.xsl : cette feuille de transformation générique supprime le contenu de tous les éléments XML à l’exception de ceux désignés par le paramètre « select » et de ses descendants (voir la ligne 43). Si le paramètre select n’est pas renseigné, aucune modification n’est effectuée. La valeur du paramètre select peut également être transmis en paramètre à la feuille XSL ;
- filter-out-p.xsl : cette feuille de transformation exemple
supprime le contenu de tous les éléments
<p>ayant un attribut@typeà la valeur ‘ouverture’ (voir l’expression XPath de la ligne 42). Elle peut être adaptée et utilisée pour filtrer le contenu de différentes balises XML à la volée ; - filter-out-sp.xsl : cette feuille de transformation exemple
supprime le contenu de tous les éléments
<sp>ayant un attribut@whoà la valeur ‘enqueteur’ (voir l’expression XPath de la ligne 42). Elle peut être adaptée et utilisée pour filtrer les prises de tour de différents locuteurs à la volée ; - filter-number-act-scene-line.xsl : cette feuille de
transformation exemple numérote tous les actes, scènes et lignes
de l’édition XML de la pièce « All’s Well That Ends Well » de
William Shakespeare publiée en ligne :
https://www.ibiblio.org/xml/examples/shakespeare/all_well.xml.
Elle peut être utilisée pour numéroter à la volée lors de l’import. Le pré-traitement XSL est strict, il est nécessaire de déposer dans le dossier source (contenant la pièce) le fichier de DTD de la pièce disponible en ligne : http://www.ibiblio.org/xml/examples/play.dtd.
Elle peut également être appliquée de façon définitive sur la pièce au préalable, avant import, avec l’aide de la macro ExecXSL ; - txm-front-teiHeader2textAtt.xsl : cette feuille de
transformation générique extrait des métadonnées de l’élément
teiHeader pour les projeter sous forme d’attributs de l’élément
text. Elle peut aider à s’affranchir d’un fichier «
metadata».
Feuilles d’adaptation de corpus particuliers
- p4top5_perseus.xsl : conversion des fichiers XML du projet http://www.perseus.tufts.edu/hopper du format TEI P4 au format TEI P5.
3-posttok
- txm-posttok-addRef.xsl : cette XSL construit des références
qui seront affichées par défaut dans les concordances. Elles
seront composées de :
- la valeur de l’attribut
@idde l’élément<text>ou, le cas échéant, du nom du fichier sans extension ; - éventuellement, le numéro de page : l’attribut
@nde la première balise<pb/>qui précède le mot (attention, ce traitement affecte sérieusement la performance sur de gros fichiers) ; - éventuellement, le numéro de paragraphe : l’attribut
@ndu premier ancêtre<p>; - éventuellement, le numéro de ligne : : l’attribut
@nde la première balise<lb/>qui précède le mot (attention, ce traitement affecte sérieusement la performance sur de gros fichiers).
- la valeur de l’attribut
- txm-posttok-unbreakWords.xsl : cette XSL permet de reconstruire certains mots qui auraient été découpés par la segmentation lexicale initiale (tokenisation), par exemple à cause de sauts de ligne ou de sauts de page situés au milieu des mots.
- txm-filter-teitextgrid-xmlw-posttok.xsl : This styleheet should be used to adjust word properties in the tokenized version of DARIAH-DE Textgrid texts.
4-edition
- 1-default-html.xsl : cette XSL permet de construire une
édition HTML supplémentaire ou de remplacement de celle construite par le module.
Elle transforme chaque élément TEI selon sa position hiérarchique par rapport aux balises de type paragraphe,<tei:p>et<tei:ab>, dans l’arbre XML:- en amont elles deviennent des
<html:div> - les
<tei:p>et<tei:ab>deviennent des<html:p> - en aval elles deviennent des
<html:span>
Par ailleurs les noms des éléments d’origine sont transférés dans l’attribut@class, ce qui permet de piloter la mise en forme des éléments depuis une feuille CSS.
Une feuille CSS modèletxm.cssest disponible dans le dossier$TXMHOME/css, à copier dans le sous-dossiercssdu dossier des sources avant de la personnaliser pour piloter la mise en forme de l’édition.
Quelques éléments ont des traitements spécifiques (des<tei:pb/>, des<tei:note>, etc.). Des<tei:head>sont transformés en<html:h2>indépendamment du niveau de la division.
Cette XSL est à utiliser conjointement avec la XSL2-default-pager.xsl;
- en amont elles deviennent des
- 2-default-pager.xsl : Cette XSL découpe chaque texte en autant de fichiers HTML
d’édition que de pages. Elle ne doit a priori pas être modifiée.
Elle est à utiliser conjointement avec la XSL1-default-html.xsl; - txm-edition-xtz-corpusakkadien-translit.xsl : XSL a utiliser pour régler les éditions translittérées de tablettes cunéiformes en Akkadien[35] ;
- txm-edition-xtz-cuneiform.xsl : XSL a utiliser pour créer les éditions de tablettes cunéiformes en Akkadien.
5.9.5.5 Ordre des textes
L’ordre des textes d’un corpus a une influence sur l’ordre d’apparition des occurrences dans les progressions ou dans les concordances, sur l’ordre des éditions de textes, etc.
Par défaut, les textes d’un corpus sont ordonnés par l’ordre
alphanumérique de leur nom de fichier source (soit la valeur de leur
propriété text@id.
Par exemple, pour un dossier source contenant trois textes « a.txt »,
« b.txt » et « c.txt », l’ordre des textes du corpus sera « a », « b »
et « c ».
Si on souhaite indiquer un ordre de textes différent de l’ordre
alphanumérique de leur nom on peut préfixer les noms de textes par un
préfixe numérique encodant l’ordre. Par exemple pour les textes précédents on
peut les renommer en « 01c.txt », « 02a.txt « et « 03b.txt » pour
obtenir l’ordre « 01c », « 02a » et « 03b ».
Une autre façon plus pratique, et recommandée, consiste à s’appuyer sur
le fichier « metadata » des sources. Si ce dernier contient une colonne nommée
« textorder » alors les textes du corpus seront ordonnés selon l’ordre
alphanumérique des valeurs de cette colonne.
Par exemple, pour un dossier source contenant trois textes et le
fichier « metadata.csv » suivant :
a.xmlcommençant par :<text id="a">A AA AAA</text>b.xml:<text id="b">B BB BBB</text>z.xml:<text id="z">Z ZZ ZZZ</text>metadata.csv:
id textorder ..
a 003
b 001
z 002
L’ordre des textes sera ‘b’, ‘z’ et ‘a’.
5.9.5.7 Options supplémentaires
Décocher le paramètre « Suppression des dossiers intermédiaires »
permet de vérifier le résultat d’un certain nombre de traitements
intermédiaires de l’import en analysant le contenu de dossiers
situés dans le dossier $TXMHOME/corpora/MONCORPUS :
- src : ce dossier contient le résultat final des étapes « 1-split-merge » et « 2-front » combinées ;
- tokenized : contient le résultat du tokeniseur et de l’étape
« 3-posttok ». Les fichiers qui s’y trouvent sont au même format
XML que les fichiers du dossier «
src» avec l’élément «<w>» en plus encodant chaque mot ; - cqp : contient la représentation du corpus directement
indexable par l’outil «
cwb-encode» du moteur « CQP ». Elle peut être importée très rapidement avec le module « CQP ».
5.9.6 Module XML-TEI BFM : import XML TEI de la Base de Français Médiéval - BFM (.xml)
5.9.6.1 Entrée
Le format d’entrée est défini dans la documentation d’encodage de la Base de Français Médiéval (BFM). Chaque texte est représenté dans un fichier au format XML TEI P5 qui encode à la fois le corps des textes et leurs métadonnées.
En plus des fichiers de textes, un fichier de paramètres appelé « import.properties » contient les expressions XPath[36] servant à extraire les métadonnées des textes dans leur entête TEI.
Voici un exemple de contenu de ce fichier:
titre=/tei:TEI/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:title[@type=‘reference’]/text()
auteur=/tei:TEI/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:author/text()
Glose :
- la valeur de la métadonnée « titre » correspond au contenu d’un
élément <title> se trouvant à un endroit précis de l’entête TEI et
dont l’attribut « type » vaut « reference » ;
- la valeur de la métadonnée « auteur » correspond au contenu d’un élément <author> se trouvant à un endroit précis de l’entête TEI.
Durant l’import, chaque mot reçoit une nouvelle propriété “ref”, qui sera utilisée pour afficher la référence par défaut des concordances. Cette propriété est construite à partir de plusieurs informations :
le sigle du texte, valeur de l’attribut text@sigle
le numéro de paragraphe, valeur de l’attribut p@n
si le texte contient des vers : le numéro de vers, valeur de l’attribut lb@n
La valeur de l’attribut text@sigle est construit lors de l’étape “importer” du module d’import en récupérant l’information, par ordre de préférence, dans :
le retour de l’XPath associée au paramètre “idbfm” déclaré dans le fichier “import.properties”
le retour de l’XPath associée au paramètre “sigle” déclaré dans le fichier “import.properties”
le nom du fichier source XML
Attention, le module d’import ne gère pas les balises TEI div1, div2, etc. Il faut les remplacer par des balises div soit directement dans les sources XML, soit à l’aide d’une feuille XSL d’entrée.
Pour plus d’informations sur l’encodage des textes de la BFM :
Manuel d’encodage XML-TEI des textes de la BFM : http://bfm.ens-lyon.fr/article.php3?id\_article=158
Consortium de la Text Encoding Initiative : http://www.tei-c.org
5.9.6.2 Annotation
Des annotations morphosyntaxiques sont ajoutés avec TreeTagger au moyen du modèle linguistique « fro.par ». Le jeu d’étiquettes utilisé par ce modèle est CATTEX2009 (voir http://bfm.ens-lyon.fr/article.php3?id_article=176).
5.9.6.3 Édition
L’édition des textes est assez proche de celle réalisée pour le projet « Queste del Saint Graal » (voir http://portal.textometrie.org/txm). Toutefois cette partie du module sera remplacée à terme par les feuilles de styles XSLT+CSS d’Alexis Lavrentiev pour produire une édition équivalente et pérenne.
5.9.7 Module XML-TEI Frantext : import XML TEI de Frantext libre (.xml)
Ce module importe des textes du corpus Frantext « textes libres de droits » encodés en XML-TEI <http://www.cnrtl.fr/corpus/frantext\>.
Les textes sont d’abord convertis au système d’encodage des textes de la BFM avec la feuille de transformation txm-filter-teifrantext-teibfm.xsl :
- l’élément ‘<br/>’ est recodé en ‘<lb/>’ ;
- les mots étoilés sont réencodés en ‘<w type=“caps”>…</w>’ ;
- l’entête TEI est corrigée, en particulier l’élément ‘<auteur>’ est converti en ‘<author>’ ;
- les éléments ‘<seg>’ sont réencodés en ‘<w>…</w>’.
puis ils sont importés par le module XML-TEI BFM (voir section 5.2.1.6 page 72 pour le détail des opérations).
5.9.8 XML TEI de TXM (.xml) : module XML-TEI TXM
5.9.8.1 Entrée
Ce module importe directement des textes au format pivot interne de TXM appelé XML-TXM[37] (diminutif de « XML-TEI TXM »). Il s’agit d’un module technique utilisé pour le développement de la plateforme TXM. Il n’est pas recommandé pour l’utilisateur non expert.
Ce module ne réalise pas de tokenisation ni de calcul d’identifiants de mots car le format XML-TXM encode déjà les mots dans des éléments « <w> ».
5.9.9 XML de Factiva (.xml) : module XML Factiva
Ce module prend en charge le format Factiva XML. Ce format n’est plus disponible pour les licences éducative et recherche de Factiva.
5.9.9.1 Entrée
Ce module prend en entrée les fichiers produit par l’export XML du portail Factiva[38]. Les fichiers sont traités puis importé à l’aide du module XML/w+CSV.
Le traitement des fichiers PPS est celui proposé par Daniel Marin et Florent Bédécarrats : il commence par restructurer les informations du header pour quelles soient exploitables par TXM.
5.9.10 Module Factiva TXT : import de fichiers au format « Export Mail » de Factiva (.txt)
Ce module convertit les fichiers sources du format export Mail Factiva au format Alceste, puis applique l’import Alceste.
5.9.10.1 Entrée
Ce module prend en entrée le format d’export Mail de Factiva, en suivant les recommandations d’export Factiva de Pierre Ratinaud et Lucie Loubere :
faites votre recherche classique ;
une fois vos articles sélectionnés, au dessus de ces derniers, dans « Options d’affichage » sélectionnez « article complet et indexation » ;
demandez à voir les articles ;
copier la totalité du contenu dans un document .txt.
5.9.11 Module Cordial+CSV : import de sorties de Cordial (.cnr)
5.9.11.1 Entrée
Corps de texte
Les textes sont des fichiers au format CNR de Cordial, c’est à dire un TSV avec comme caractère séparateur de colonne la tabulation et sans caractère de champ.
Dans l’ordre, les colonnes des fichiers CNR sont :
para : le numéro de paragraphe
sent : le numéro de phrase
form : la forme graphique d’une unité lexicale
lem : le lemme
pos : la propriété morphosyntaxique
func : la fonction syntaxique
Métadonnées de texte
Les métadonnées des textes sont encodées dans le fichier « metadata » situé dans le même dossier que les fichiers sources.
Le séparateur de colonnes est « , ». Le caractère de champ[39] est « “ ».
La première ligne d’entête nomme chaque métadonnée.
La première colonne doit être nommée « id », les suivantes sont nommées à la discrétion de l’utilisateur mais sans utiliser de caractères accentués ou spéciaux.
La première colonne doit contenir le nom du fichier source (sans extension) qui correspond aux métadonnées de la ligne.
5.9.11.2 Sortie
On obtient en sortie des structures pour les paragraphes (p), les phrases (s) et les textes (text). Les mots sont équipés de toutes les propriétés correspondant aux colonnes CNR.
5.9.12 Module IraMuTeQ-Alceste : import de texte brut encodé par des étoiles de type Alceste-IraMuTeQ (.txt)
5.9.12.1 Entrée
Ce module prend en entrée un fichier au format utilisé par le logiciel Alceste (format également utilisé par IRaMuTeQ - http://www.iramuteq.org). Il s’agit d’un format de texte brut utilisant quelques conventions d’encodage simples.
Pour encoder un début de texte (qui correspond à l’« uci », unité de contexte initiale dans la terminologie d’Alceste) et ses métadonnées, il y a deux façons de faire au choix :
une ligne de la forme : 0001 *Meta1_Val1 *Meta2_Val2… *MetaN_ValN
une ligne de la forme : **** *Meta1_Val1 *Meta2_Val2… *MetaN_ValN
*Meta_val, déclare une métadonnée de texte dont « Meta » est le nom et « val » la valeur. Si une métadonnée de texte n’a pas de valeur, on peut utiliser la notation suivante : *Meta.
Pour TXM, les noms d’attribut sont composés uniquement de lettres sans distinction de casse tout sera ramené en minuscules) et sans diacritique (sans accent).
Pour pré-encoder un mot composé, on peut remplacer les espaces entre ses constituants par un caractère « _ ». Par exemple, « l’assemblée_nationale » peut être segmenté en deux mots : « l’ » et « assemblée_nationale ».
Le format Alceste propose également un moyen de coder des sections à l’intérieur des uci, sections caractérisées par une variable étoilée (notation : -*Meta_Val sur une ligne), mais ce module d’import TXM ne le gère pas encore.
5.9.13 Module Hyperbase : import de texte brut encodé par des esperluettes de type Hyperbase (.txt)
5.9.13.1 Entrée
Ce module prend en entrée un fichier au format Hyperbase (version PC). c’est à dire avec des lignes séparatrices de textes de la forme suivante :
…
&&& Nom du texte long, NomduTexte, NomCourt &&&
…
Les lignes de saut de pages (codées par « \$ ») sont interprétées. Elles se répercutent par des structures p.
5.10 Module d’importation de transcriptions d’enregistrements
5.10.1 Module XML Transcriber+CSV : import de XML selon la DTD Transcriber (.trs)
5.10.1.1 Entrée
Corps de texte
Ce module prend en entrée un dossier de transcriptions au format XML-TRS (extension ‘.trs’). Elles doivent être accompagnées du fichier « trans-14.dtd » pour être valides. Chaque transcription sera considérée comme une seule unité textuelle.
Les transcriptions doivent correspondre au Guide de Transcription d’entretiens Transcriber-TXM 0.3_FR
Métadonnées de texte
Les métadonnées des textes sont encodées dans le fichier « metadata » situé dans le même dossier que les fichiers sources, voir la section 5.6 page ??.
Plan textuel des enquêteurs
Ce module gère un plan textuel spécifique, appelé “plan des enquêteurs”, des discours de certains locuteurs à exclure des analyses. Par exemple, ignorer les questions et les commentaires des enquêteurs pour ne travailler que sur le discours des répondants à une enquête.
Ce plan est défini par une colonne de métadonnée appelée interviewer-id-regex qui encode, pour chaque transcription, une expression régulière de reconnaissance de codes de locuteurs d’enquêteurs. Par exemple, la valeur ‘ENQ’ codée dans cette colonne pour une transcription ‘A’ définira tous les tours de parole du locuteur ENQ comme étant ceux d’un enquêteur. Cette notion d’enquêteur est alors mobilisable à travers le paramètre Indexer les tours d'enquêteur (voir la section Paramètres).
Exemples de définition de plans d’enquêteurs dans un fichier metadata
| id | interviewer-id-regex |
|---|---|
A |
ENQ |
B |
ENQ.* |
C |
Jean|Pierre |
Glose :
- tous les tours du locuteur ‘ENQ’ de la transcription A.trs sont considérés comme des tours d’enquêteurs
- tous les tours de locuteurs dont le code commence par ‘ENQ’, par exemple ‘ENQ1’, ‘ENQ2’ ou encore ‘ENQ10’ de la transcription B.trs sont considérés comme des tours d’enquêteurs
- tous les tours des locuteurs ‘Jean’ et ‘Pierre’ de la transcription C.trs sont considérés comme des tours d’enquêteurs
Paramètres
Ce module dispose d’une section de paramètres spécifique nommée “Transcription” qui contient les paramètres suivants :
Afficher le locuteur: Afficher ou non le code du locuteur au début de chaque tour de parole, « vrai » par défaut (paramètre coché). Cette option est utile - en décochant le paramètre - dans le cas de monologues où la distinction entre locuteurs n’est pas pertinente et où l’affichage du code peut rendre la lecture de la transcription moins fluide.Indexer les tours d'enquêteur: Indexer ou non les mots des tours de paroles de locuteurs identifiés comme étant des « enquêteurs » dans le tableau de métadonnées (voir la section “Métadonnées de texte”), « vrai » par défaut (paramètre coché). Cette option est utile - en décochant le paramètre - pour n’appliquer les outils de la textométrie (concordance, index…) que sur le discours de locuteurs spécifiques (ou « répondants » à des « enquêteurs » dont le discours n’est pas l’objet de l’étude textométrique). Par contre les discours des « répondants » et des « enquêteurs » restent toujours retranscripts ensemble dans les Éditions des transcriptions pour pouvoir disposer de la lecture de la totalité du contexte de production d’un discours donné. Ce paramètre définit le plan textuel des “enquêteurs” dont le fonctionnement est analogue à celui du plan textuel du “Hors texte à éditer” du module d’import XML-TEI Zero + CSV.Nouvelle page pour chaque section: Changer de page ou non au début de chaque section des transcriptions (« vrai » par défaut). Si cette option est décochée la pagination suit les paramètres définis dans la section Édition du formulaire de paramètres (mots par page, etc.).Utiliser les métadonnées Transcriber: Intégrer ou non les métadonnées Transcriber dans les métadonnées des transcriptions (« vrai » par défaut). Cette option est utile pour transmettre certaines informations qui pourraient ne pas avoir été encodées dans le tableau de métadonnées (comme le nom du transcripteur).
5.10.1.2 Sortie
La structure des fichiers XML de Transcriber est reproduite :
une section Transcriber correspond à la structure div ;
un tour de parole correspond à la structure « u » (pour ‘utterance’, de la TEI) ;
un segment de parole correspond à la structure sp.
Les deux formes d’événements Transcriber sont gérées :
ponctuels : commentaires, bruit court ;
sur séquence de mots : prononciation, incertitudes…
Les descriptions associées aux événements ponctuels sont portées par le mot suivant.
Pour les événements à séquences, les descriptions sont concaténées dans la propriété lexicale « event » des mots compris entre les événements « begin » et « end ».
Certaines métadonnées sont dupliquées au niveau des mots (spk) et des
structures
(u@spkattrs, textAttr@<metadata>, div@topic@endtime@starttime@type, sp@speaker@endtime@starttime@overlap,
event@type@desc) pour faciliter la construction de sous-corpus.
5.10.1.4 Édition
L’édition reproduit celle de Transcriber. On retrouve au début de chaque texte (ou transcription) la liste des métadonnées correspondantes.
Les textes sont paginés par nombre de mots après un tour de parole ou bien par sections.
Les événements et commentaires apparaissent entre crochets en italique.
Les indications de synchronisation apparaissent en exposé et disposent d’un bouton “Lecture” [![]() ] pour lire l’enregistrement à partir du point de synchronisation.
] pour lire l’enregistrement à partir du point de synchronisation.
voir les différents utilitaires TXM utiles pour faire ces conversions à la section ?? page ??.↩︎
TXM est livré avec un utilitaire appelé
TXT2XMLfacilitant la conversion par lot de fichiers TXT vers XML.↩︎c’est-à-dire que n’importe quelles balises sont utilisées.↩︎
le « /w » dans le nom du module exprime le fait que le module interprète spécifiquement les balises XML
<w>…</w>dans les sources comme encodant directement des unités lexicales (mots).↩︎ignorer du contenu textuel délimité par certaines balises.↩︎
par exemple un traitement de texte – MS Word ou LibreOffice Writer, ou un lecteur de fichier PDF – Adobe Acrobat, ou un navigateur web – FireFox ou Internet Explorer ouvert sur une page, ou encore un logiciel de messagerie – Thunderbird, etc.↩︎
raccourcis clavier « Control-A », ou « Command-A » en Mac, pour sélectionner tout le texte.↩︎
raccourcis clavier « Control-C », ou « Command-C » en Mac↩︎
au format .xlsx, .ods ou .csv↩︎
tous les modules dont le nom se termine par
+ CSVpeuvent utiliser un tableau de métadonnées « metadata »↩︎nécessite la présence du logiciel LibreOffice sur la machine↩︎
par défaut l’encodage est Unicode UTF-8, sinon il faut déclarer l’encodage dans le préambule XML (par exemple
<?xml version="1.0" encoding="cp1252"?>)↩︎Le standard Unicode existe depuis le début des années 1990, mais sa diffusion a pris un certain temps selon les logiciels et les systèmes d’exploitation. En 2022, son usage n’est pas encore complètement généralisé↩︎
à partir de 1987↩︎
l’algorithme de recherche de l’encodage est d’abord lancé sur l’ensemble des textes, pour trouver une valeur générale. Puis texte par texte. Si un texte est trop petit, la valeur générale est utilisée.↩︎
les erreurs proviennent principalement : 1. des mots inconnus du logiciel ; 2. des lemmes dont les formes sont homographes et difficiles à départager seulement par les catégories grammaticales (par construction, TreeTagger ne distinguera pas par ailleurs les lemmes homographes ayant une même catégorie grammaticale. Par exemple, le lemme du verbe « [voler1] dans un avion » ne sera pas distingué du lemme du verbe « [voler2] à l’étalage ». Les deux lemmes seront encodé « voler » (sans distinction des entrées de dictionnaire ou de sens)) ; 3. des mots dont le contexte immédiat de quelques mots avant et après ne permet pas de lever l’ambiguïté sur la catégorie grammaticale (dans ce cas TreeTagger peut annoter plusieurs interprétations sur le même mot, en les séparant par une barre verticale ‘|’) ; 4. enfin, il y a des phrases dont la structure syntaxique est d’apparence ambiguë (par exemple dans la phrase « la petite brise la glace », il est particulièrement difficile pour un logiciel de déterminer si « brise » et « glace » sont resp. un
verbebrise suivi d’unnomglace ou unnombrise suivi d’unverbeglace, sans connaissances supplémentaires sur le texte)↩︎un exemple de fichier de modèle TreeTagger pour le français médiéval est disponible à l’adresse http://bfm.ens-lyon.fr/spip.php?article324↩︎
contrairement aux requêtes CQL du moteur CQP qui s’expriment avec des expressions régulières PCRE - voir la section 7.20.↩︎
qui correspond au nom de l’élément TEI w standard.↩︎
qui correspond au nom de l’élément TEI pb standard.↩︎
qui correspond au nom de l’élément TEI text standard.↩︎
qui correspond au nom de l’élément TEI sp standard.↩︎
même si le standard XML permet d’utiliser des noms de balises mélangeant minuscules, majuscules et lettres accentuées dans les sources des corpus, en particulier pour nommer des structures internes de textes, le moteur CQP les normalise de façon drastique en minuscules et sans accents pour des raisons internes au moment de l’import. Donc il faut bien les désigner en minuscules et sans accents dans ce paramètre.↩︎
Le fichier « metadata.csv » doit par défaut être au format suivant : le séparateur de colonne est « , » ; le séparateur de texte est « “ » ; l’encodage des caractères doit être UTF-8. Ces paramètres sont modifiables dans les préférences « TXMUtilisateurImport » à la section « format du fichier metadata.csv ».↩︎
on aurait pu utiliser « De Gaulle » directement ici, ou n’importe quelle autre chaîne de caractères. Utiliser « dg » ici peut permettre de simplifier des requêtes de construction de sous-corpus ou de partitions, plus tard dans l’exploitation du corpus.↩︎
noter la normalisation nécessaire du mot sans accents.↩︎
le tableau « metadata » peut d’ailleurs contenir des informations de « gestion du corpus » qui ne sont pas forcément utilisées lors de l’analyse avec TXM↩︎
les règles française ou anglaise sont appliquées, en fonction du code de la langue :
fr, resp.en.↩︎lb pour line break, cb pour column break et pb pour page break↩︎