10 Extensions
Les fonctionnalités de TXM peuvent être augmentées par l’ajout d’extensions.
Pour ajouter une extension, voir la section 3.3 « Installer une extension ».
Cette section documente les extensions disponibles.
10.1 Extension « Annotation URS »
Cette extension est documentée dans la section 8.3 « Annotation avec un modèle Unité-Relation-Schéma (URS) au fil du texte ».
10.2 Extensions « TreeTagger software » et « TreeTagger en, fr models »
Les extensions « TreeTagger software » et « TreeTagger en, fr models » fonctionnent de concert pour appliquer le logiciel TreeTagger sur les corpus de textes en langue anglaise ou française au moment de leur importation dans TXM.
10.2.1 Annotation linguistique automatique
L’application du logiciel TreeTagger ajoute automatiquement des catégories morphosyntaxiques et des lemmes aux mots. Par exemple, pour le français :
- les catégories morphosyntaxiques seront ajoutées sous la forme d’une nouvelle propriété de mots appelée
frpos; - les lemmes seront ajoutés sous la forme d’une nouvelle propriété de mots appelée
frlemma.
Les catégories morphosyntaxiques ajoutées sont documentées pour chaque langue :
Les lemmes correspondent aux formes normalisées sans flexion des mots c’est à dire aux entrées de dictionnaire : par exemple l’infinitif pour les verbes, le masculin-singulier pour les substantifs et les adjectifs.
10.2.2 Mise en oeuvre dans TXM
L’installation de ces deux extensions est décrite dans la section 3.2 « Installer TreeTagger pour ajouter automatiquement des propriétés morphosyntaxiques et des lemmes aux mots ».
Le réglage de ces deux extensions est décrit dans la section 5.3.3 « Langue principale » documentant le formulaire de paramètres d’importation de corpus dans TXM.
D’autres langues peuvent être traitées par TreeTagger, y compris des variantes du français et de l’anglais. Pour cela il faut les ajouter à TXM en suivant la procédure manuelle décrite dans la section B.1 Télécharger les fichiers depuis le web et les préparer de la page d’installation des modèles de langues supplémentaires de TreeTagger.
10.2.3 Paramétrage de TreeTagger
L’appel de TreeTagger peut être configuré à partir de paramètres supplémentaires de la page de préférences « TXM > Avancé > TAL > TreeTagger » :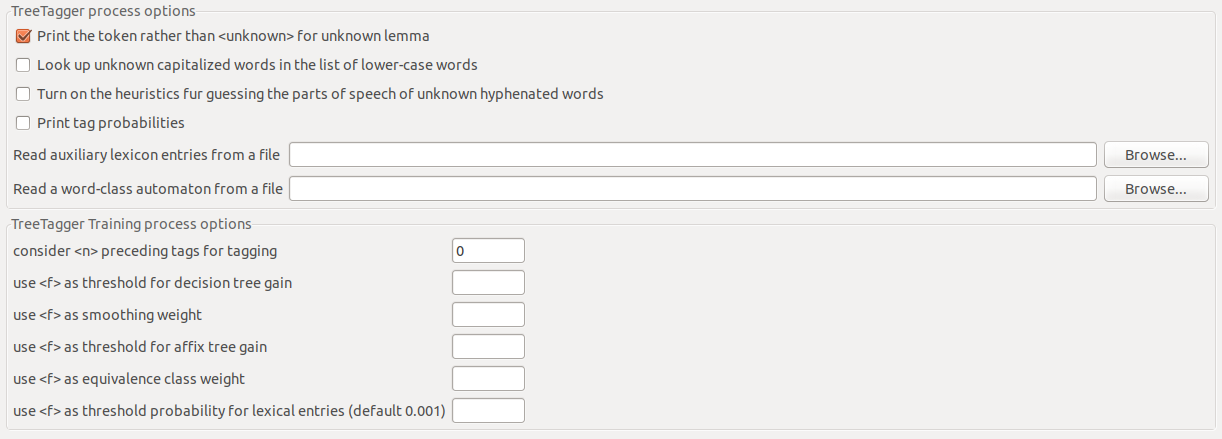
Figure 10.1: Préférences de paramètres d’appel de TreeTagger.
10.2.3.1 Paramètres d’étiquetage (TreeTagger process options)
Paramètres d’application d’un modèle de langue :
Print the token rather than <unknown> for unknown lemma(truepar défaut)- pour les mots inconnus, il est plus intéressant d’utiliser la forme du mot comme lemme plutôt que le lemme générique « <unknown> ».
- mettre à
falsepermet de découvrir les lemmes inconnus.
Look up unknown capitalized words in the list of lower-case words- pour autoriser le traitement de mots en majuscules inconnus comme des formes équivalentes en minuscules présentent dans le modèle de langue.
Turn on the heuristics for guessing the parts of speech of unknown hyphenated words- pour utiliser l’heuristique de détermination de la catégorie morpho-syntaxique des mots césurés inconnus
Print tag probabilities- ajouter une propriété encodant la probabilité d’attribution de la catégorie morpho-syntaxique
Read auxiliary lexicon entries from a file- utiliser un fichier de lexique complémentaire (au format un mot par ligne, voir la documentation de TreeTagger)
Read a word-class automaton from a file- utiliser un fichier d’automate de classe de mots (voir la documentation de TreeTagger)
10.2.3.2 Paramètres d’apprentissage (TreeTagger training process options)
Paramètres d’apprentissage d’un modèle de langue :
consider <n> preceeding tags for tagging0par défaut
- taille de la fenêtre de mots à utiliser pour désambiguiser le choix de la catégorie morpho-syntaxique
use <f> as threshold for decision tree gain- seuil de gain pour l’arbre de décision (voir la documentation de TreeTagger)
use <f> as smoothing weight- poids de lissage
use <f> as threshold for affix tree gain- seuil de gain pour l’arbre d’affixes
use <f> as equivalence class weight- poids des classes d’équivalence
use <f> as threshold probability for lexical entries (default 0.001)- seuil de probabilité pour le choix de mot
10.3 Extension « Annotation Syntaxique »
L’extension « Syntactic Annotation » (ou Annotation Syntaxique) ajoute des fonctionnalités d’importation et d’exploitation d’annotations syntaxiques entre les mots des phrases au moyen de deux types d’annotations :
- CoNLL-U : sous la forme de nouvelles propriétés de mots encodant les dépendances syntaxiques entre les mots selon le modèle Universal Dependencies ou UD50
- TIGER : sous la forme d’arbres syntaxiques selon le modèle TIGER
Les relations UD sont directement exploitables avec le moteur CQP.
Les arbres TIGER sont exploitables avec le moteur spécialisé TIGERSearch.
Nous présentons les principaux outils disponibles dans l’ordre de leur usage, accompagnés d’exemples.
10.3.1 Importation d’informations syntaxiques dans TXM
TXM peut importer des informations syntaxiques soit :
- en important (ou chargeant) des corpus annotés en syntaxe aux formats CoNLL-U ou TIGER-XML, c’est à dire en créant un nouveau corpus TXM ;
- en important des annotations syntaxiques, aux formats CoNLL-U ou TIGER-XML, au sein d’un corpus TXM pré-existant.
Remarque : TXM ne permet pas encore d’annoter en syntaxe à la volée lors de l’import d’un corpus comme il le fait avec TreeTagger pour la lemmatisation.
Les importations d’annotations syntaxiques (B) permettent de combiner l’usage de la syntaxe avec toutes les services habituels des corpus TXM : structures textuelles, autres annotations de mots, éditions élaborées, relations aux fichiers média (images, sons, vidéos), etc. Il repose sur un partage d’identifiants de mots entre les fichiers d’annotations syntaxiques et le corpus TXM.
10.3.1.1 Import de corpus annotés en syntaxe (A)
Les corpus annotés en syntaxe sont importés respectivement par :
- pour la syntaxe CoNLL-U (UD) : le module
Fichier > Importer > Corpus > CoNLL-U + CSV - pour la syntaxe TIGER : le module
Fichier > Importer > Corpus > XML-TIGERSearch
10.3.1.2 Import d’annotations syntaxiques (B)
Les annotations syntaxiques CoNLL-U sont injectées dans des corpus pré-existants avec deux commandes :
- pour plusieurs fichiers .conllu :
Fichier > Importer > Annotations > Import CoNLL-U Annotations from directory… - pour un seul fichier .conllu :
Fichier > Importer > Annotations > Import CoNLL-U Annotations from file….
Les annotations syntaxiques TIGER sont injectées dans des corpus pré-existants avec la commande Fichier > Importer > Annotations > Importer des annotations TIGERSearch depuis un répertoire….
Les mots (terminaux) des annotations syntaxiques doivent encoder un identifiant qui correspondra à ceux des mots du corpus TXM pour que la projection puisse fonctionner. Pour le format CoNLL-U, cet identifiant sera encodé dans la colonne MISC sous la forme XmlId=w_xxx, w_xxx étant la valeur de l’attribut @id des éléments <w> des mots des fichiers pivots du corpus TXM (au format XML TEI TXM).
Remarques :
- pour produire des fichiers d’annotations syntaxiques qui serviront à une injection, le plus simple est d’exporter les textes du corpus TXM au format CoNNL-U avec la commande
Fichier > Exporter > Corpus > in CoNLL-U format (.conllu), qui encodera les identifiants de mots dans la colonne MISC. On peut ensuite utiliser un parseur acceptant le format CoNLL-U en entrée et qui préserve le contenu d’entrée de la colonne MISC. - attention, si le corpus n’est pas segmenté en phrases (par exemple avec une balise
<s>), l’export produit un fichier avec une phrase par mot.
Nous allons maintenant présenter comment importer puis exploiter un corpus annoté en syntaxe au format CoNLL-U (avec le module d’import “CoNLL-U + CSV”). L’import de corpus au format TIGER et l’import d’annotations syntaxiques seront détaillés dans la section de référence “Autres outils d’importation d’informations syntaxiques CoNLL-U ou TIGER”.
10.3.2 Importation d’un corpus au format CoNLL-U
Le module d’import “CoNLL-U + CSV” prend en entrée un répertoire de fichiers au format CoNLL-U d’extension .conllu (un texte par fichier).
Le corpus créé contient de façon imbriquée :
- une structure
<text>par fichier source correspondant au texte défini par le fichier CoNLL-U (voir ci-dessous comment est déterminée l’unité textuelle) - des structures
<p>correspondant aux paragraphes CoNLL-U, encodés par les lignes#newpar id - des structures
<s>correspondant aux phrases CoNLL-U - des mots dans les phrases dont les propriétés sont issues des colonnes UD. Leur nom correspond à celui de la colonne préfixé par défaut par “ud-” (ce préfixe est paramétrable dans les préférences de TXM)
10.3.2.1 Indexation des mots par le moteur TIGERSearch
Ce paramètre d’import permet de créer des arbres TIGER à partir des mots CoNLL-U, pour un requêtage avec TIGERSearch :
- il nécessite l’installation de
Perl - chaque fichier CoNLL-U est d’abord converti au format TIGER-XML par un script Perl, les phrases trop longues (plus de 100 mots) étant ignorées à cause des limites de TIGERSearch (il n’y a pas de limite pour le nombre de phrases)
- puis un fichier driver TIGER est créé pour rassembler tous ces fichiers dans un corpus TIGER
- une fois indexé par TIGERSearch, le corpus peut être interrogé à la fois par CQP et par TIGERSearch
Installation et paramétrage de Perl :
- Ubuntu : installé par défaut, sinon
sudo apt install perl - Mac OS X : installé par défaut, sinon télécharger et installer Perl
- Windows : télécharger et installer Strawberry Perl
Pour Windows seulement, indiquer le chemin vers Perl dans la page de préférences
TXM > Utilisateur > Script > Perl > Chemin de l'exécutable Perl, exemple :C:/StrawberryPerl/perl/bin
10.3.2.2 Identification des unités textuelles
Par default, TXM créé un texte du corpus par fichier “CoNLL-U” en utilisant le nom du fichier sans l’extension .conllu comme identifiant .
Le paramètre d’import ‘Utiliser les commentaires “#newdoc id”’ de la section “CoNLL-U” permet de délimiter et de donner un identifiant aux textes à partir des lignes “#newdoc id” du format CoNLL-U. Si le fichier ne contient pas de telles lignes, le nom du fichier est utilisé.
10.3.2.3 Gestion des mots contractés
Le format CoNLL-U encode les mots contractés (multi-word surface token - MWT) et les mots “syntaxiques” correspondants sur plusieurs lignes de mots UD.
Par exemple la contraction de surface “des” est encodée sur trois lignes, comme dans l’exemple suivant :
| ID | FORM | LEMMA | UPOS | XPOS | FEATS | HEAD | DEPREL | DEPS | MISC |
|---|---|---|---|---|---|---|---|---|---|
| 6-7 | des | _ | _ | _ | _ | _ | _ | _ | _ |
| 6 | de | de | ADP | _ | _ | 8 | case | _ | _ |
| 7 | les | le | DET | _ | Definite=Def|Number=Plur|PronType=Art | 8 | det | _ | _ |
- une ligne d’ID 6-7 pour la forme de surface “des”, sans propriétés syntaxiques (_)
- une ligne d’ID 6 pour le premier mot syntaxique “de”, avec ses propriétés syntaxiques
- une ligne d’ID 7 pour le deuxième mot syntaxique “le”, avec ses propriétés syntaxiques
TXM permet de choisir comment sont indexées ces trois lignes au moment de l’import du corpus à l’aide du paramètre ‘Gestion des contractions’ de la section “CoNLL-U” selon trois modes :
Surface (mode par défaut) : seules les lignes des formes contractées de surface sont indexées. Les lignes encodant les mots syntaxiques ne sont pas indexées mais leurs propriétés sont intégrées aux propriétés des formes contractées sous forme concaténée (en utilisant le ‘.’ comme séparateur).
Usage : dans ce mode les dénombrements lexicaux sont compatibles avec ceux des autres modules d’import de TXM. La sélection de mots syntaxiques est réalisée indirectement par le biais de requêtes portant sur les propriétés des mots contractés. Les éditions de textes rendent compte de la transcription de surface (habituelle) des textes. Les propriétés de mots affichées par survol rendent compte des propriétés des mots syntaxiques.
Syntaxe : seules les lignes des mots syntaxiques sont indexées. Les lignes encodant les formes contractées de surface ne sont pas indexées mais leur forme (la valeur de la colonne “FORM”) est intégrée dans la propriété MISC des mots syntaxiques.
Usage : dans ce mode les dénombrements lexicaux sont affectés par la multiplication des mots syntaxiques. La sélection de mots contractés est réalisée indirectement par le biais de requêtes portant sur les propriétés des mots syntaxiques (propriété MISC). Les éditions de textes affichent les mots syntaxiques à la place des formes de surface des mots contractés. Les propriétés de mots affichées par survol rendent compte des propriétés des mots syntaxiques et des formes de surface des mots contractés.
Tout : toutes les lignes UD sont indexées, les formes contractées de surface et les mots syntaxiques.
Usage : dans ce mode les dénombrements lexicaux sont affectés à la fois par la duplication des mots contractés et des mots syntaxiques et par la multiplication des mots syntaxiques. La sélection de mots contractés ou de mots syntaxiques se fait directement. Les éditions de textes affichent à la fois les formes de surface des mots contractés et les mots syntaxiques. Les propriétés de mots affichées par survol rendent compte des propriétés des mots syntaxiques ou des formes de surface des mots contractés.
10.3.2.4 Projection de propriétés UD
La projection de propriétés UD entre mots parents et mots dépendants permet d’exprimer des requêtes syntaxiques directement en CQL, en copiant les propriétés syntaxiques de parents dans leurs dépendants et inversement.
Deux paramètres d’import permettent de gérer ces projections :
Propriétés de parents à projeter : indiquer la liste des propriétés UD à projeter vers leurs dépendants séparées par des virgules ; Par défaut : “upos,deprel”
Les propriétés crées dans les mots dépendants sont préfixées par “ud-head-” + nom de la propriété projetée
Propriétés de dépendants à projeter : indiquer la liste des propriétés UD à projeter vers leur parent séparées par des virgules ; Par défaut : “upos,deprel”
Les propriétés crées dans les mots parents sont préfixées par “ud-deps-” + nom de la propriété projetée
[SLH] valeurs concaténées quand plusieurs dépendants ?
10.3.3 Exemples de corpus annotés en syntaxe au format CoNLL-U à importer dans TXM
[SLH] TODO Exemple PUD FR
https://universaldependencies.org/treebanks/fr_pud/
This is a part of the Parallel Universal Dependencies (PUD) treebanks created for the CoNLL 2017 shared task on Multilingual Parsing from Raw Text to Universal Dependencies.
http://universaldependencies.org/conll17/
[SLH] TODO Exemple PROFITEROLE
Corpus exemple PROFITEROLE-GOLD-V1-0_conllu pour l’import CoNLL-U + CSV
Télécharger le corpus depuis PROFITEROLE-GOLD-V1-0_conllu.zip
Extraire les fichiers de l’archive.
Lancer le module d’import
Fichier > Importer > Corpus > CoNLL-U + CSVsur le répertoirePROFITEROLE-GOLD-V1-0-CONLLU/conlluet nommer le corpus “PROFITEROLE-GOLD-V1-0”.
10.3.4 Exploitation d’informations syntaxiques
Ce manuel va d’abord présenter comment exploiter des annotations syntaxiques UD avec le moteur de recherche CQP. L’exploitation d’annotations syntaxiques avec le moteur de recherche TIGERSearch sera présentée à la section “Exploitation d’annotations syntaxiques avec le moteur TIGERSearch”.
10.3.4.1 Exploitation d’annotations syntaxiques UD avec le moteur de recherche CQP
10.3.4.1.1 Modèle syntaxique et morpho-syntaxique Universal Dependencies (UD)
Dans la représentation CoNLL-U51 des phrases, chaque mot est pointé par le mot qui le gouverne, appelé gouverneur ou tête, (propriété ud-head) avec un lien étiqueté par une relation de dépendance syntaxique définie par le projet Universal Dependencies ou UD (propriété ud-deprel). Chaque mot est également étiqueté par une partie du discours dont le jeu est défini par le même projet (propriété ud-upos). Par exemple, la syntaxe de la phrase “La Loi est l’expression de la volonté générale.” est représentée par des relations et des étiquettes comme illustré à la figure 10.2 :
- les relations syntaxiques sont représentées par des arcs étiquetés par la relation de dépendance ;
- les parties du discours sont affichées dans une boîte bleue ;
- la racine est ici le mot “expression”.

Figure 10.2: Visualisation des relations syntaxiques dépendantielles UD.
Remarque : N’hésitez pas à utiliser la démo en ligne d’UDPipe pour tester ce modèle sur vos propres phrases.
10.3.4.1.2 Principales propriétés de mots syntaxiques et morpho-syntaxiques disponibles dans TXM
Pour l’exploitation CQP, ces informations sont disponibles sous la forme de propriétés de mots.
Propriétés syntaxiques
ud-id: numéro du mot dans la phrase syntaxique52 (1 à n)ud-head: numéro du mot gouverneur dans la phrase (ou 0 pour la racine)ud-deprel: relation de dépendance UD au mot gouverneurExemples de valeurs :
- ‘root’ = [je suis la] racine de la phrase (verbe conjugué, participe ou nom)
- ‘aux’ = verbe auxiliaire
- ‘nsubj’ = sujet nominal
- ‘obj’ = objet direct
- ‘iobj’ = objet indirect
- ‘obl’ = oblique
- ‘nmod’ = modifieur nominal
- ‘det’ = déterminant
- ‘conj’ et ‘cc’ = conjonctions de subordination et de coordination
- ‘ccomp’ et ‘xcomp’ = complément propositionnel essentiel ou contrôlé par un argument du niveau supérieur
ud-head-deprel= relation de dépendance du mot gouverneur lui-même (copie de son ud-deprel)ud-dep-deprel= liste des relations de dépendance des mots gouvernés (sous la forme ‘|dep1|dep2|dep3…|’)ud-deps: liste augmmentée des relations de dépendance sous la forme de paires ‘head:deprel’ (permet d’indiquer plusieurs gouverneurs pour un mot, en cas de coordination notamment)
Propriétés morpho-syntaxiques
ud-upos: partie du discours UD- ‘VERB’ = verbe
- ‘AUX’ = auxiliaire
- ‘PRON’ = pronoun
- ‘ADV’ = adverb
- ‘NOUN’ = nom
- ‘PROPN’ = nom propre
- ‘NUM’ = numéral
- ‘SYM’ = symbole
- ‘DET’ = déterminant
- ‘ADJ’ = adjectif
- ‘ADP’ = préposition
- ‘PART’ = particule
- ‘CCONJ’ = conjonction de coordination
- ‘SCONJ’ = conjonction de subordination
- ‘PUNCT’ = punctuation
- ‘INTJ’ = interjection
- ‘X’ = autre
ud-feats: liste des propriétés morpho-syntaxiques UD, sous la forme ‘Definite=Def|Gender=Fem|Number=Sing|PronType=Art’ (que l’on appelle parfois ‘sous-catégories’)
[AL] Il faudrait ajouter des pipe au début et à la fin pour pouvoir utiliser l’opérateur CQL contains
ud-xpos: autre partie du discours spécifique à une langue ou issue d’un autre jeu d’étiquettes
Autres propriétés
10.3.4.2 Outil de visualisation : Arbres syntaxiques
La commande “Arbres syntaxiques”, bouton avec l’icone d’arbre dans la barre d’outils, affiche une représentation graphique de la structure syntaxique de chaque phrase des textes du corpus.
10.3.4.2.1 Choix de la visualisation
Si une représentation TIGER est disponible pour le corpus, la commande affiche l’arbre TIGER par défaut :
knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/arbre-conll-tiger.png)Sinon la commande affiche l’arbre UD :
- soit de la librarie DepTreeViz : knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/arbre-conll-ud.png)
Visualisation UD - DepTreeViz - soit de la librarie Brat : knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/ud-brat-visu.png)
Visualisation UD - Brat
On peut choisir entre ces deux représentations (‘TIGER’ ou ‘UD’) à l’aide du menu déroulant situé en haut à gauche.
10.3.4.2.3 Visualisation de la phrase dans l’édition
Le bouton “Édition” (icone de livre) permet d’afficher et mettre en évidence la phrase dans le contexte de l’édition.
10.3.4.2.4 Recherche syntaxique
La recherche s’active à partir du bouton “Loupe” en bas à gauche dans la barre de navigation :


Après ouverture de la recherche
Le moteur de recherche dépend de la visualisation affichée :
- TIGER : requête TIGER
- UD : requête CQP
- Fonctionnement : les requêtes CQP se feront dans le sous-corpus “ud-s” pour limiter les résultats aux limites de phrases. Cela réduit l’accès aux structures suppérieures et il faut passer par une requête de la forme
[_structure_property="..."]>[AL : je ne comprends pas… Justement, les requêtes sur structures supérieures ne serait plus possibles. ]
- Fonctionnement : les requêtes CQP se feront dans le sous-corpus “ud-s” pour limiter les résultats aux limites de phrases. Cela réduit l’accès aux structures suppérieures et il faut passer par une requête de la forme
Une fois l’interface de recherche ouverte et la requête rentrée, il faut cliquer sur le bouton de calcul habituel des commandes de TXM pour effectuer al recherche.
La navigation se fait alors par phrase ayant matché avec la requête. Puis par match ayant matché dans la phrase. Le match affiché est mis en évidence dans l’arbre :
- TIGER : le match est en rouge knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/tiger-tree-visu-with-match.png)
- UD : commence par “[” et finit par ”]” knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/ud-tree-visu-with-match.png)
10.3.4.2.5 Retour vers l’arbre syntaxique
Il est possible de retourner à l’arbre syntaxique TIGER ou UD depuis les commandes Edition et Concordance. Il faut pour cela sélectionner un mot de l’édition ou une ligne de la concordance puis ouvrir le menu contextuel et sélectionner Lien vers l'arbre syntaxique
>[AL : Attention : dans mon TXM ça affiche “Syntactic tree concordance link” (dans l’édition et concordance). Il faut supprimer “concordance” ?]
10.3.4.2.6 Autres paramètres
Choix des propriétés de NT et T à afficher pour les représentations :
- TIGER : une ou plusieurs propriétés de mot (T terminal) et une propriété d’arc (NT non-terminal)
- UD - DepTreeViz : un ou plusieurs champs UD de mot (terminal) et un ou plusieurs champs UD (non-terminal)
- UD - Brat : pas de réglage possible pour l’instant. Eventuellement, le code UD de la phrase peut-être édité mais les nouvelles valeurs n’impacteront que l’affichage de l’arbre courant.
10.3.4.3 Outils d’exploitation CQP
Nous présentons l’utilisation de requêtes UD (il s’agit de requêtes CQP limitées aux sous-corpus “ud-s” des phrases UD. Il est construit à l’aide de la requête CQP suivante [ud-id="1"] [ud-id !="1"]+ [:ud-id="1|__UNDEF__":]) pour l’extraction syntaxique à partir de quatre exemples :
- l’
Indexdes fonctions syntaxiques d’un mot particulier - l’
Indexdes objets d’un verbe particulier [TODO à faire] - l’
Indexdes relations sujet-verbe-objet [TODO possible ?]
- la
Concordancedes phrases de structures syntaxique objet-sujet-verbe (OSV)
Ces requêtes syntaxiques sont également utilisables dans toutes les commandes utilisant une requête UD (ou CQL) : Progression, Références, etc.
10.3.4.3.1 Afficher les fonctions syntaxiques du pronom « nous »
knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/index-nous.png)10.3.4.3.2 Concordance de toutes les phrases de la forme OSV (proposition principale)
[TODO simplifier les requêtes grâce le mode de requête UD knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/ud-search-mode.png) –> fait (AL)] Construisons la requête progressivement :
- pour les phrases à verbes conjugués
- je cherche un Objet :
[ud-deprel="obj"]- qui dépend du verbe principal :
[ud-deprel="obj" & ud-head-deprel="root"]
- qui dépend du verbe principal :
- puis 0 à n mots :
[]* - puis un Sujet :
[ud-deprel="nsubj" & ud-head="root"] - puis 0 ou n mots :
[]* - puis un Verbe :
[ud-deprel="root" & ud-upos="VERB"] - requête finale :
oobas [ud-deprel="obj" & ud-head-deprel="root"][]* [ud-deprel="nsubj" & ud-head-deprel="root"] []* [ud-deprel="root" & ud-upos="VERB"]
- je cherche un Objet :
- pour les phrases à verbes auxilaires
- pour retrouver les phrases avec un verbe auxiliaire, on modifie le dernier élément comme Auxiliaire qui dépend de la racine de la phrase
- requête finale :
oobas [ud-deprel="obj" & ud-head-deprel="root"][]*[ud-deprel="nsubj" & ud-head-deprel="root"] []* [ud-deprel="aux" & ud-head-deprel="root"]
- on combine les deux types de phrases :
- pour retrouver les deux, on combine les conditions de verbes avec l’opérateur « | » (OU) et des parenthèses
- requête finale :
oobas [ud-deprel="obj" & ud-head-deprel="root"] []* [ud-deprel="nsubj" & ud-head-deprel="root"] []* [(ud-deprel="root" & ud-upos="VERB" ) | (ud-deprel="aux" & ud-head-deprel="root")]
- que l’on applique dans une Concordance :
knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/conc-sov.png)
Concordance des phrases en OSV - on peut bien sûr désigner un des mots de la requête par un label ‘@’ pour le mettre en évidence dans le pivot de la concordance. Par exemple le sujet ici :
oobas [ud-deprel="obj" & ud-head-deprel="root"] []* @[ud-deprel="nsubj" & ud-head-deprel="root"] []* [(ud-deprel="root" & ud-upos="VERB" ) | (ud-deprel="aux" & ud-head-deprel="root")]
10.3.4.4 Outils Exploitation TIGERSearch
10.3.4.4.1 Index et Concordance
L’extension ajoute un nouveau moteur de résolution de requêtes appelé TIGERSearch (de diminutif “TIGER” dans l’interface de TXM) aux champs de requêtes des outils Index, PartitionIndex, Progression, Referencer et Concordance. Une requête TIGER exprime une sélection de noeuds syntaxiques à l’aide de contraintes syntaxiques appliquées aux nœuds non terminaux et terminaux (mots) du corpus. Elle s’écrit en utilisant la syntaxe du langage de requête TIGERSearch.
Si la requête contient le label “#pivot” alors seuls les mots dominés par le noeud “#pivot” sélectionné seront sélectionnés. Sinon, les résultats sélectionneront l’ensemble des mots dominés par les nœuds TIGER sélectionnés.
Voir le tutoriel Concordances KNIC pour d’autres exemples.
10.3.4.5 Utilitaires TIGER
Des outils supplémentaires sont disponibles à partir du menu principal TXM : Utilitaires > tiger > exploit. Ces outils sont livrés sous la forme de macros (scripts Groovy) modifiables depuis la vue “Macro” dans le sous-répertoire tiger.
TIGER Summary
Pour une requête TIGER donnée, affiche le nombre de matchs obtenus, sous-graphes inclus ou pas.
Si la sélection est multiple (ex: plusieurs sous-corpus sélectionnés ; une partition sur des textes sélectionnée) alors le résultat est tabulé avec un sous-corpus/partie par colonne.
Le dénombrement ne prend en compte que les matchs TIGER limités aux positions des corpus de la sélection (liste de matchs des sous-corpus/parties) → combinaison requêtes TIGER x requêtes CQL.
Paramètres :
- tiger_query : “[]” par défaut
- count_subgraph : “true” par défaut
Résultat :
PROFITEROLE-GOLD-V1-0 F 422211
TIGER Index
Affiche un index hiérarchique des valeurs de propriétés de noeuds de matchs TIGER.
Les noeuds sont repérés par un ou plusieurs labels dans la requête TIGER. Les labels peuvent être positionnés sur des noeuds terminaux ou non-terminaux.
L’utilisateur doit alors indiquer les labels de noeuds à utiliser et les propriétés à projeter, pour chaque label.
La macro peut prendre une sélection de sous-corpus ou une partition. Qui génèrera une liste de corpus/sous-corpus : C1, C2, … CN. La macro produira alors une colonne par sous-corpus/partie.
Paramètres :
- tiger_query : “[]” par défaut
- labels : liste des nœuds labelisés
- properties : liste des propriétés des nœuds labelisés
- count_subgraph : “true” par défaut
- sort_column : “freq” (défaut) ou “labels”
- max_lines : -1 (défaut, pas de limite)
Exemple:
Paramètres :
- tiger_query :
#pivot:[pos="VERB"] & #clause:[cat="root" & type="VFin"] & #clause >L #pivot & #clause >D #obj:[cat=("obj"|"ccomp"|"obj\:advneg"|"obj\:advmod")] & #clause >D #suj:[cat=("nsubj"|"csubj")] & #obj >L #objhead:[] & #suj >L #sujhead:[] & #sujhead .* #pivot & #pivot .* #objhead & #sujhead:[pos=("NOUN"|"PROPN")]
- labels :
sujhead,pivot,objhead - properties :
pos,mor,pos - count_sub_matches : coché
- sort_column :
freq ▼ - max_lines :
-1 - debug :
OFF ▼
- tiger_query :
Résultat :
pos, mor, pos F FROSRCMFUD3 NOUN_VerbForm=Fin_NOUN 20 NOUN_VerbForm=Fin_VERB 4 NOUN_Tense=Past_VerbForm=Part_NOUN 4 PROPN_VerbForm=Fin_NOUN 3 NOUN_VerbForm=Inf_NOUN 2 PROPN_VerbForm=Fin_PROPN 2 PROPN_Tense=Past_VerbForm=Part_NOUN 1 NOUN_VerbForm=Fin_PROPN 1 PROPN_VerbForm=Inf_NOUN 1 NOUN_VerbForm=Inf_PRON 1 NOUN_VerbForm=Fin_ADV 1 PROPN_VerbForm=Fin_PRON 1 NOUN_VerbForm=Fin_PRON 1
TIGER Ratio
Affiche le rapport entre le nombre de matchs de 2 requêtes TIGER, sous-graphes inclus ou pas.
(l’implémentation se fait par l’appel successif de la macro TIGER Summary avec les 2 requêtes)
Paramètres :
- tiger_query_A
- tiger_query_B
- count_subgraph
Exemple :
- tiger_query_A :
#pivot:[pos="VERB"] & #clause:[cat="root" & type="VFin"] & #clause >L #pivot & #clause >D #obj:[cat=("obj"|"ccomp"|"obj\:advneg"|"obj\:advmod")] & #clause >D #suj:[cat=("nsubj"|"csubj")] & #obj >L #objhead:[] & #suj >L #sujhead:[] & #sujhead .* #pivot & #pivot .* #objhead //SVO// - tiger_query_B :
#pivot:[pos="VERB"] & #clause:[cat="root" & type="VFin"] & #clause >L #pivot & #clause >D #obj:[cat=("obj"|"ccomp"|"obj\:advneg"|"obj\:advmod")] & #clause >D #suj:[cat=("nsubj"|"csubj")] & #obj >L #objhead:[] & #suj >L #sujhead:[] & #sujhead .* #objhead & #objhead .* #pivot //SOV//
- tiger_query_A :
Résultat :
[FROSRCMFUD:1335] [FROSRCMFUD:3510] R = 1335 / 3510 = 0,38
TIGER SVO Summary
Calculer des statistiques sur les différentes combinaisons de S (ujet), V(erbe) et O(bjet) (les 6 sont possibles en ancien français), en tenant compte :
- de la nature de S et de O (nom, pronom personnel, …), mais aussi (ce peut être des requêtes successives) :
- de la détermination ou non du nom (si S et/ou O = nom) : présence ou non d’un article (et si oui, de quel type : défini, indéfini, possessif…)
- de la complexité de S et de O (longueur en nombre de mots, mais aussi complexité « linguistique »: présence d’une subordonnée relative, d’un complément du nom…)
- de la complexité du verbe : forme simple ou composée (temps composé, modal + infinitif…)
Paramètres :
- output_file : fichier ODS de sortie
- input_queries_table : fichier de tableau ODS, excel, tsv des compléments de requêtes
- count_sub_matches :
- sujet_value : \[cat=("nsubj"|"csubj")\] (par défaut)
- object_value : \[cat=("obj"|"ccomp"|"obj\\\\:advneg"|"obj\\\\:advmod")\] (par défaut)
- clauses : types de propositions décomptées
- clauses_counts_main : true (par défaut)
- clauses_counts_subordinate : false
- clauses_counts_inserted : false
- output_queries : affiche les colonnes de requêtes TIGER utilisées
Résultat :
Génère un tableau ODS avec les colonnes suivantes : measure, value, qSVO, SVO, qSOV, SOV, qOSV, OSV, qOVS, OVS, qVSO, VSO, qVOS, VOS. Les colonnes ’q*’ contiennent les requêtes TIGER utilisées pour calculer chaque cellule.
[TODO voir + de détails https://groupes.renater.fr/wiki/txm-info/public/spec_exploitation_annotation/calculs_syntax_sov#v1]
10.3.5 Exportation d’informations syntaxiques
10.3.5.1 Export d’un corpus au format CONLL-U
Pour créer des fichiers *.connlu contenant les mots du corpus. Chaque fichier encode un texte du corpus.
Paramètres :
- encoding : encodage des caractères des fichiers *.conllu, UTF-8 par défaut
- sentenceStructure : permet d’indiquer si une structure CQP du corpus encode les phrases et de construire les phrases CoNLL correspondantes
- lemmaProperty : permet d’indiquer si une propriété CQP du corpus encode le lemme des mots. La valeur sera projetée dans le champ LEMMA
- posProperty : permet d’indiquer si une propriété CQP du corpus encode la morphosyntaxe des mots. La valeur sera projetée dans le champ UPOS
10.3.5.2 Export des propriétés CoNLLU au format CONLL-U
Permet d’exporter les propriétés CQP encodant les propriétés CoNLLU. Sélectionner le corpus à exporter puis lancer la commande.
Paramètres :
- conlluResultDirectory : dossier où les fichiers conllu seront écris
- propertiesPrefix : préfix des propriétés CQ encodant les champs UD
Paramètres optionels :
- commentaires
- insertParagraphs : les paragraphes seront codés dans les commentaires UD à partir de la structure CQP “p”
- detectGap : si activé, des commentaires “gap” seront inséré quand la propriété d’un mot CQP “gap” vaut “next”
- tokens
- insertNoSpaceAfter : si activé, les paramètre “NoSpaceAfter” sont ajouté dans le MISC UD
- insertTokenWithoutUDAnnotations : si activé, les tokens sans propriétés UD renseignés seront aussi ajouté dans l’export. Sinon seul les token ayant les propriétés UD (au minimum “ID”) seront exportés.
- valeurs par défaut des propriétés UD
- defaultFormPropertyName: l’export utilisera la valeur de cette propriété CQP si la propriété préfix + “form” n’est pas renseignée
- defaultFormPropertyName: l’export utilisera la valeur de cette propriété CQP si la propriété préfix + “lemma” n’est pas renseignée
- …
- phrases :
- openingPunct : option de correction des débuts de phrases. Lorsque la forme du premier token d’une phrase match, il est déplacé dans la phrase précédente
10.3.6 Autres outils d’importation d’informations syntaxiques CoNLL-U ou TIGER
10.3.6.1 Importation d’un corpus au format TIGER
[TODO SLH à vérifier + terminologie ‘XML-TS’, etc.]
Le module peut importer des sources TIGER-XML sous deux formes différentes :
- soit un fichier corpus.xml et plusieurs fichiers subcorpus.xml. Il est disponible à coté des autres modules dans le menu
Fichier > Import > XML-TIGERSearch. - soit un fichier TIGER-XML complet par texte sans fichier driver ; un fichier driver par défaut sera généré.
Le module crée un corpus CQP à partir des noeuds terminaux des fichiers TIGER-XML et un corpus TIGER (qui sera utilisé pour résoudre les requêtes TIGER).
Le corpus CQP créé contient :
- un “text” par fichier subcorpus du XML-TS dont l’identifiant est
extrait du fichier master
- si un fichier metadata est présent dans le répertoire des sources, les metadonnées sont injectées dans le corpus CQP.
- une structure “s” par sentence TIGER
- un mot par noeud terminal dont les propriétés sont extraites directement des features des noeuds terminaux (T)
10.3.6.2 Corpus exemple PROFITEROLE-GOLD-V1-0_tiger-xml pour l’import TIGER
Télécharger le corpus depuis PROFITEROLE-GOLD-V1-0_tiger-xml.zip
Lancer le module d’import Fichier > Importer > Corpus > CoNLL-U + CSV sur le répertoire PROFITEROLE-GOLD-V1-0-tiger-xml/tiger-xml et nommer le corpus “PROFITEROLE-GOLD-V1-0”.
10.3.6.2.1 J’ai déjà des propriétés UD dans mon corpus
Dans le cas où les mots d’un corpus portent déjà des informations UD dans les propriétés CQP (avec un import XML/w par exemple, pour que les commandes liées à UD soient actives, il faut régler un prefix UD pour que les outils de TXM utilisent les bonnes propriétés.
Par défaut, les outils utilisent les propriétés préfixées par “ud-” :
- ud-id
- ud-form ou word si ud-form n’est pas présent
- ud-lemma (optionel)
- ud-upos (optionel)
- ud-xpos (optionel)
- ud-feats (optionel)
- ud-head (optionel)
- ud-deprel (optionel)
- ud-deps (optionel)
- ud-misc (optionel)
Un autre préfixe peut être indiqué avec la commande Edition > CoNLLU Corpus preferences du menu principal disponible lorsque le corpus est sélectionné dans la vue corpus.
10.3.6.3 Importation d’annotations syntaxiques dans un corpus existant
Ce tutoriel présente la procédure d’ajout d’annotations syntaxiques à un corpus importé avec le module “XML TEI Zero + CSV”. Il est ainsi possible de combiner les avantages du balisage TEI (structuration du des documents, apparat critique, éditions personnalisées…) avec l’annotation syntaxique.
10.3.6.3.1 Pré-requis
- Annotations syntaxiques au format CONLL-U synchronisées avec le fichiers XML-TEI TXM du corpus
- la jointure se fait par la présence dans la colonne MISC (10) de l’annotation
XmlId=w\_textId\_wordNqui correspond à l’identifiant du mot (w/@*:id) dans les fichiers XML-TEI TXM
- la jointure se fait par la présence dans la colonne MISC (10) de l’annotation
- et/ou Annotations syntaxiques au format TIGER-XML
Exemple de synchronisation :
- Fichier XML TEI TXM
xml <w id="w_AlexisProlRaM_1"> <txm:form>Ici</txm:form> <txm:ana resp="#src" type="#cattex-pos">ADVgen</txm:ana> </w>
- Fichier CONLL-U
1 Ici ici ADV ADVgen _ 2 advmod _ XmlId=w_AlexisProlRaM_1- Fichier TIGER-XML
xml <t id="s1_1" word="Ici" pos="ADV" mor="_" lemma="ici" textid="StAlexis_1050_verse" editionId="w_AlexisProlRaM_1"/>
10.3.6.3.2 Annoter en syntaxe un corpus TXM
L’opération la plus simple consiste à :
- Exporter son corpus au format CoNLL-U : menu Fichier > Exporter > Corpus > au format CoNLL-U
- Appliquer son outils d’annotation préféré ou avec l’un des outils répertorié sur le site d’Universal Dependencies
- Importer les annotations en suivant les instructions de la section suivante
10.3.6.3.3 Importation au format CoNLL-U
- Charger la version du corpus PROFITEROLE-GOLD-V1-0 sans annotations syntaxiques PROFITEROLE-GOLD-V1-0_nosynt.txm
- Télécharger et extraire l’archive des annotations au format CONLL-U PROFITEROLE-GOLD-V1-0_conllu.zip
- Créer un dossier “Annotations” dans le répertoire de travail et décompresser l’archive téléchargé dans ce dossier
- Dans TXM, sélectionner le corpus “PROFITEROLE-GOLD-V1-0”
- Lancer l’importation avec la commande
Fichier > Importer > Annotations > Import CONLL-U Annotations from directory...avec les paramètres suivants :- conlluDirectory : sélectionner le répertoire
Annotations/conllu - propertiesPrefix : ud-
- udPropertiesToImport : form,lemma,upos,xpos,feats,head,deprel,deps
- overwrite_cqp_properties : (non coché)
- normalize_word_ids : (non coché)
- headPropertiesToProject : deprel,upos
- depsPropertiesToProject : deprel, upos
- conlluDirectory : sélectionner le répertoire
- Attendre la fin de l’injection des annotations (ça peut prendre quelques minutes)
- Un message “TXM 0.8.2 Ne répond pas” peut s’afficher pendant le processus, il faut l’ignorer ou cliquer sur “Attendre”
- Sélectionner le corpus PROFITEROLE-GOLD-V1-0 et lancer la commande “Informations”
- les annotations syntaxiques doivent apparaître comme de propriétés de mots portant le préfixe UD “ud-”
- Faire un index de requête CQL :
[ud-deprel="root"](têtes de toutes les phrases) - Visualiser les arbres syntaxiques (UD) des phrases du corpus :
- commande “Arbres syntaxiques” (icone knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/synttrees-icon.png))
10.3.6.3.4 Importation au format TIGER-XML
- Télécharger l’archive des annotations au format TIGER-XML PROFITEROLE-GOLD-V1-0_tiger-xml.zip
- Extraire l’archive dans le répertoire “Annotations” créé lors de la recette précédente.
- Attention : dû à un bug, le chemin du répertoire ne doit pas contenir d’accent dans son nom (voir #2869) et il faut que le dossier se trouve sur un disque local (et non sur un “disque réseau”).
- Sélectionner le corpus “PROFITEROLE-GOLD-V1-0”
- Lancer l’importation avec la commande “Fichier > Importer >
Annotations > Importer des annotations TIGERSearch”
- Dans la boite de dialogue, sélectionner le répertoire ‘Annotationq/tiger-xml’ des fichiers TIGER-XML.
- Valider et attendre la fin de l’import des annotations
- Faire une concordance de la requête TIGER
- commande “Concordance”, sélectionner “TIGER” dans la liste déroulante avant le champ de requête (icone knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/searchenginesicon.png) à côté de l’Assistant de requête)
- vérifier que la ponctuation est bien présente dans les contextes
- faire un retour au texte et vérifier que la ponctuation est bien présente > #pivot:[pos=“VERB”] & > #clause:[cat=“root” & type=“VFin”] & #clause >L #pivot & #clause > >D #obj:[cat=(“obj”|“ccomp”|“obj:advneg”|“obj:advmod”)] & > #clause >D #suj:[cat=(“nsubj”|“csubj”)] & #obj >L #objhead:[] & > #suj >L #sujhead:[] & #objhead .* #pivot & #pivot .* #sujhead
- Visualiser les arbres syntaxiques correspondant à la requête TIGER ci-dessus
- commande “Arbres syntaxiques” (icone knitr::include_graphics(“images/manuel-extension-annotation-syntaxique/synttrees-icon.png))
- Comparer les résultats, attention la concordance affiche une ligne par sous-graphe TIGER.
10.4 Extension « Media Player »
L’extension « Media Player » permet de jouer un extrait de vidéo ou d’audio depuis TXM.
L’extrait peut correspondre à la totalité d’un fichier ou d’un flux média ou à un extrait définit par une commande de TXM, comme les commandes Concordances ou Édition, à partir d’une transcription d’enregistrement.
Dans le deuxième cas il s’agit d’un « retour à la source » spécialisé pour les corpus multimédia, complémentaire au « retour au texte » classique (de la transcription).
10.4.1 Retour à la vidéo ou à l’audio depuis le résultat d’une commande TXM
Cette fonctionnalité est disponible pour les corpus de transcriptions d’enregistrements compatibles avec l’extension Media Player, comme le corpus exemple « P1S8 ».
La section 10.4.6 « Création d’un corpus de transcriptions compatible avec l’extension Media Player » présente les différents moyens d’en créer.
10.4.1.1 Depuis une concordance
Le retour à la vidéo ou à l’audio est opéré soit :
- depuis le menu contextuel d’une ligne de concordance (clic droit) en lançant la commande « Jouer le média »
- en sélectionnant une ligne de concordance puis en saisissant le raccourcis clavier « Ctrl-Màj-M »
Dans les deux cas, le passage contenant le pivot de la ligne est joué dans le lecteur multimédia intégré à TXM (la section 10.4.4 « Stratégies de construction d’empans de lecture » présente les différentes options de réglage des caractéristiques du passage).
Si l’édition de la transcription était déjà ouverte, le lecteur vidéo s’ouvre à côté de la transcription :
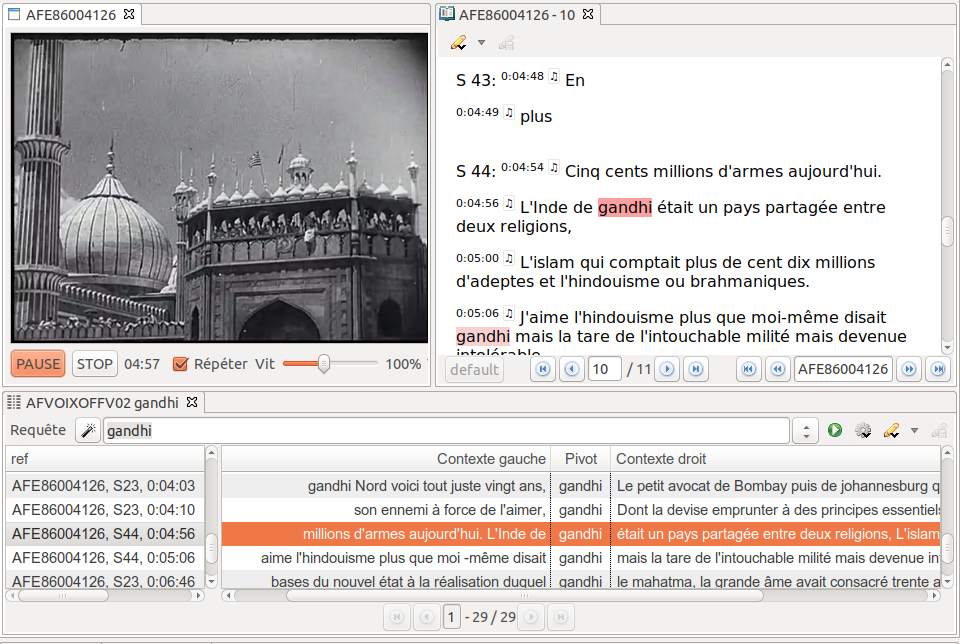
Figure 10.3: Retour à la vidéo d’une transcription automatique des commentaires d’un sujet des Actualités Françaises du 30 janvier 1968.
10.4.1.2 Depuis une édition
Le retour à la vidéo ou à l’audio est opéré soit :
- depuis les boutons de lecture « ♫ » situés en début de section, de tour ou d’énoncé
- depuis une sélection de mots, pour les transcriptions synchronisées aux mots près :
- sélectionner les mots de la transcription dont on veut visualiser/écouter l’enregistrement
- depuis le menu contextuel (clic droit) lancer la commande « Jouer le média »
En cas d’erreur de lecture de la vidéo ou de l’audio, un message de diagnostic est affiché dans la console de TXM.
10.4.1.3 Barre d’outils du lecteur multimedia

Figure 10.4: Barre d’outils du lecteur multimédia.
La barre d’outils est composée des élements suivants :
- bouton « PAUSE/REPRENDRE » : suspendre la lecture / reprendre la lecture
- bouton « STOP » : arrêter la lecture
- indication de position « 04:57 » dans le média (minutes:secondes)
- curseurs de lecture dans la durée totale de l’enregistrement :
- début de l’empan joué
- position de la lecture
- fin de l’empan joué
- option « Répéter » la lecture de l’empan en boucle
- option « Vit » : curseur de réglage de la vitesse de lecture, de 40% (x0,4) à 140% (x1,4) de la vitesse originale de lecture de l’enregistrement
- option « Vol » : curseur de réglage du volume de lecture, de 0% à 100% du volume de lecture
10.4.2 Lecture directe d’enregistrement vidéo ou audio
La commande « FichierOuvrir un fichier média… » permet de jouer un fichier vidéo ou audio directement à partir :
- d’un dossier local, se trouvant sur la machine exécutant TXM : cliquer sur le bouton « […] » pour naviguer jusqu’au fichier ;
- d’une adresse web : par exemple
https://mp4studio.ina.fr/lire/0tfeS_XRwVxMA3VJB7CXLDWJBONpLnXPltMy6DE_1RC13c0hsEhDetDCIEvUS4d-ZnXnaOEsNoF7OuI_-hC1lelZqwlrLC-KzVjJcsiKoYRgbO4s0S39Xz9ttoiRbzwA_Qas0jEc5ib4bnPlszIFuBw58. Copier/Coller l’adresse dans le champ « Saisir le chemin de fichier ou l’adresse web (URL) ».
10.4.3 Paramètres généraux du lecteur multimedia
Les paramètres sont modifiables dans la page de préférences « TXMUtilisateurMedia PLayer » :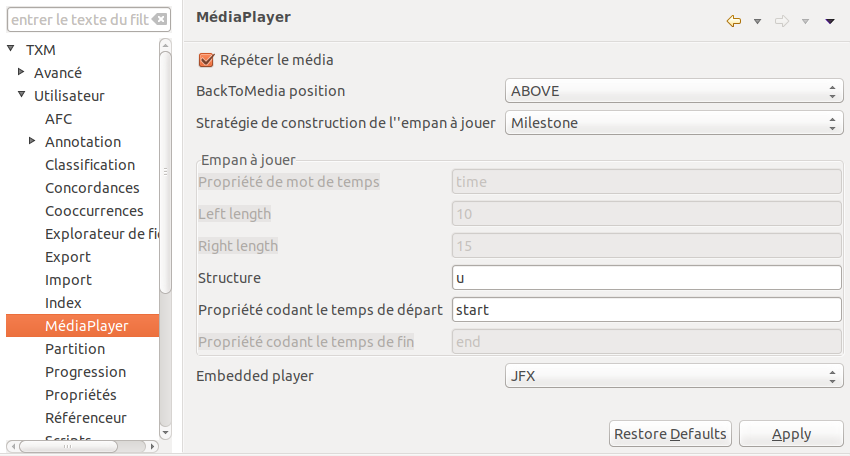
Figure 10.5: Paramètres du lecteur multimedia.
Répéter la lecture:
lecture de l’empan en boucleBackToMedia position:
emplacement du lecteur à l’ouverture, par rapport à la fenêtre de concordance ou à la fenêtre d’édition, soit :- « ABOVE » : au dessus
- « BELOW » : sous
- « LEFT_OF » : à gauche
- « RIGHT_OF » : à droite (emplacement par défaut)
Stratégie de construction de l’empan à jouer:- « Word » : à partir de propriétés de mots
- « Structure » : à partir de propriétés d’une structure
- « Milestone » : à partir d’une propriété de structure
voir le détail des stratégies à la section suivante.
10.4.4 Stratégies de construction d’empans de lecture
Ces paramètres sont réglés dans la section « Empan à jouer » des préférences « TXMUtilisateurMedia PLayer ».
10.4.4.1 Word
L’empan est construit à partir de positions de mots dans l’enregistrement, encodées dans une propriété des mots, du nième mot à gauche au mième mot à droite autour du mot pivot :
Propriété de mot de temps: nom de la propriété encodant la position du (début du) mot dans l’enregistrement, « time » par défautLeft length: position du mot dans le contexte gauche du pivot, « 10ème » mot par défautRight length: position du mot dans le contexte droit du pivot, « 15ème » mot par défaut
10.4.4.2 Structure
L’empan est construit à partir de positions de début et de fin d’une structure dans l’enregistrement :
Structure: « sp » (tour de parole) par défautPropriété codant le temps de départ: « start » par défautPropriété codant le temps de fin: « end » par défaut
Pour une sélection de mots, TXM utilise la structure qui domine la position du premier mot de la sélection.
10.4.4.3 Milestone
L’empan est construit à partir d’une position de début d’une structure dans l’enregistrement :
Structure: « u » (énoncé) par défautPropriété codant le temps de départ: « start » par défaut
Pour une sélection de mots, TXM utilise le temps de début de la structure qui précède la position du premier mot et le temps de début de la structure qui suit la position du dernier mot de la sélection.
10.4.5 Paramètres de corpus du lecteur multimedia
Le lecteur multimédia utilise certains paramètres de corpus s’ils sont présents.
Ils ont priorité sur les paramètres généraux du lecteur, qui sont modifiables dans la page de préférences.
Pour visualiser les paramètres d’un corpus relatifs au lecteur multimédia :
- d’abord sélectionner le corpus dans la vue Corpus
- ensuite lancer la commande « ÉditionPréférences Média Player » :
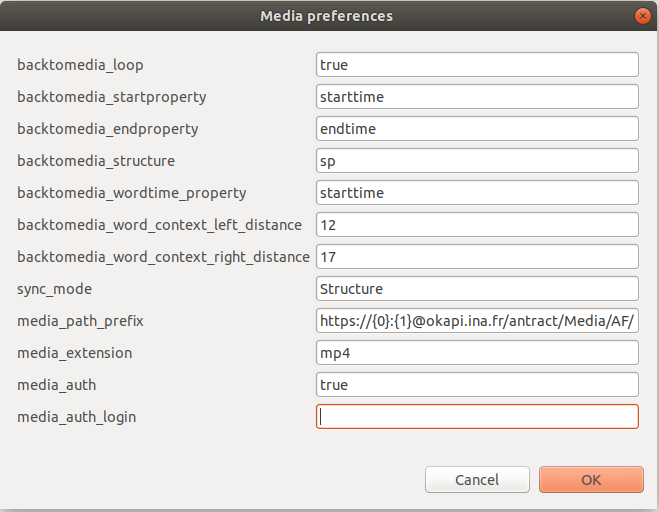
Figure 10.6: Paramètres de corpus pour le lecteur multimédia.
Paramètres généraux
Une première série de paramètres de corpus permet de régler au corpus près les paramètres généraux du lecteur multimédia (voir leur description à la section ??).
Il s’agit des huit premiers paramètres de la figure 10.6.
Le tableau 10.2 liste la correspondance entre ces paramètres de corpus et les paramètres généraux du lecteur multimédia :
| Paramètres de corpus pour le lecteur multimédia | Paramètres généraux du lecteur multimédia | Valeur par défaut | Modifiable |
|---|---|---|---|
backtomedia_loop |
Répéter la lecture |
true |
oui |
backtomedia_startproperty |
Propriété codant le temps de départ |
starttime |
non |
backtomedia_endproperty |
Propriété codant le temps de fin |
endtime |
non |
backtomedia_structure |
Structure |
sp |
oui |
backtomedia_wordtime_property |
Propriété de mot de temps |
starttime |
non |
backtomedia_word_context_left_distance |
Left length |
12 |
oui |
backtomedia_word_context_right_distance |
Right length |
17 |
oui |
sync_mode |
Stratégie de construction de l’empan à jouer |
Structure |
oui |
Les paramètres de corpus pour le lecteur multimédia ont vocation à être livrés avec le corpus pour une utilisation optimale du lecteur multimédia.
Certains de ces paramètres peuvent être modifiés en fonction des besoins d’utilisation du corpus par l’utilisateur, ils sont marqués par « oui » dans la colonne « Modifiable » :
sync_modebacktomedia_word_context_left_distancebacktomedia_word_context_right_distancebacktomedia_structurebacktomedia_loop
Pour modifier leur valeur il suffit de cliquer dans la cellule de valeur et de la modifer, puis enregistrer en cliquant sur « OK ».
Il est recommandé de ne pas modifier les autres paramètres de corpus relatif au lecteur multimédia, au risque que le retour à la vidéo ou à l’audio ne fonctionne plus.
10.4.5.1 Paramètres d’accès aux fichiers médias
Une deuxième série de paramètres de corpus permet de configurer la façon avec laquelle le lecteur multimédia accède aux fichiers médias des transcriptions d’un corpus.
Il s’agit des quatre derniers paramètres de la figure 10.6.
Stratégie d’accès aux fichiers média par défaut
Par défaut, le lecteur multimédia cherche le fichier vidéo ou audio associé à une transcription d’un corpus dans le dossier $TXMHOME\corpora<identifiant corpus>\media.
Le chemin d’accès à ce dossier est donc construit à partir de l’identifiant du corpus (<identifiant corpus>).
Le nom du fichier média lui-même est construit à partir de l’identifiant de la transcription, soit <text@id>.<extension>. C’est à dire la valeur de la métadonnée id de la structure text correspondant à la transcription, soit le nom du fichier source de la transcription sans son extension, suivie d’une extension de fichier média.
Selon le type de média, l’<extension> prend la valeur :
- « .mp4 » ou « .avi » ou « .mov » pour les fichiers vidéos ;
- « .mp3 » ou « .ogg » ou « .wav » pour les fichiers audio.
Le chemin d’accès complet par défaut au fichier média d’une transcription est donc $TXMHOME\corpora<identifiant corpus>\media<text@id>.<extension>.
Il est construit à partir de deux informations :
- l’identifiant du corpus :
<identifiant corpus>; - l’identifiant de la transcription
<text@id>.
Configuration de la stratégie d’accès aux fichiers média
Un groupe de paramètres de corpus permet de gérer différentes configurations d’accès aux fichiers média :
- en désignant un dossier local précis pour les fichiers média ;
- en désignant un site web distant hébergeant les fichiers média en ligne avec accès direct ou avec contrôle d’accès par connexion par identifiant/mot de passe.
Ces paramètres sont à régler de façon combinée :
media_path_prefix:
c’est en donnant une valeur à ce paramètre que l’on configure un accès aux fichiers média différent de la stratégie d’accès par défaut. la valeur peut être :- un chemin relatif de dossier local (à la machine) :
par exemplemon-corpus\media, les fichiers média utilisés auront le cheminmon-corpus\media<text@id>.<media_extension>
- un chemin relatif de dossier local (à la machine) :
- un chemin absolu de dossier local :
par exempleC:\Users<identifiant utilisateur>\corpus\mon-corpus\media, les fichiers média utilisés auront le cheminC:\Users<identifiant utilisateur>\corpus\mon-corpus\media<text@id>.<media_extension>
- un chemin absolu de dossier local :
- le préfixe d’une adresse59 de site web pour un accès direct à des fichiers média hébergés en ligne :
par exemplehttps://mp4studio.ina.fr/lire/, les fichiers média auront le cheminhttps://mp4studio.ina.fr/lire/<text@id>.<media_extension>
- le préfixe d’une adresse59 de site web pour un accès direct à des fichiers média hébergés en ligne :
- le préfixe d’une adresse de site web pour un accès avec contrôle d’accès, avec connexion par identifiant et mot de passe, à des fichiers média hébergés en ligne :
dans ce cas :
- le préfixe doit comprendre deux mots-clés, encadrés d’accolades (
{..}) :{0}sera remplacé par l’identifiant de connexion{1}sera remplacé par le mot de passe par exemplehttps://{0}:{1}@okapi.ina.fr/antract/Media/AF/, les fichiers média auront le cheminhttps://<identifiant de connexion>:<mot de passe>@okapi.ina.fr/antract/Media/AF/<text@id>.<media_extension>
- le préfixe d’une adresse de site web pour un accès avec contrôle d’accès, avec connexion par identifiant et mot de passe, à des fichiers média hébergés en ligne :
media_auth:
choix du mode d’accès direct ou avec contrôle d’accès par connexion.- la valeur
trueprovoque l’ouverture d’une boite de dialogue de saisie des identifiant et mot de passe de connexion lors du premier accès à un fichier média. dans ce cas, le paramètremedia_path_prefixdoit être de type d) (voir ci-dessus) - la valeur
falsecorrespond aux modes d’accès directs : type a), b) et c), aucune boite de dialogue de connexion n’est ouverte
- la valeur
media_auth_login: (paramètre optionnel) identifiant de connexion à utiliser dans la boite de dialogue de saisie des identifiant et mot de passe de connexion.
le champ « identifiant » sera pré-rempli avec la valeur de ce paramètre.
remarque : les identifiants de connexion étant des éléments de sécurité, il peut être plus sûr de ne pas utiliser ce paramètre dans certains contextes. pour des raisons de sécurité, le mot de passe ne peut pas faire partie des paramètres d’un corpus.
par contre, il n’est à saisir qu’une seule fois pour l’ensemble de la session TXM (il n’est à saisir que lors de la première demande d’accès à un fichier média).media_extension:
extension de fichier à utiliser pour les fichiers média.
par exemple :- « .mp4 » pour des fichiers vidéos
- « .mp3 » pour des fichiers audio
Configurations types
En résumé, voici des exemples de configurations types :
accès local à des vidéos
media_path_prefix:C:\Users<identifiant utilisateur>\corpus\mon-corpus\mediamedia_auth:falsemedia_auth_login: (vide)media_extension:mp4
accès distant sans connexion à des vidéos
media_path_prefix:https://mp4studio.ina.fr/lire/media_auth:falsemedia_auth_login: (vide)media_extension:mp4
accès distant avec connexion à des vidéos
media_path_prefix:https://{0}:{1}@okapi.ina.fr/antract/Media/AF/media_auth:truemedia_auth_login:<identifiant utilisateur>media_extension:mp4
10.4.6 Création d’un corpus de transcriptions compatible avec l’extension Media Player
Le module d’import « XML Transcriber + CSV » permet de créer des corpus compatibles avec l’extension Media Player.
10.4.6.1 Méthode 1. Ajouter des fichiers média dans les sources du corpus
Il faut d’abord équiper le dossier des sources avec les fichiers média :
- créer une dossier « media » dans le dossier des sources.
- y ajouter un fichier média par transcription, en utilisant comme nom de fichier l’identifiant de la transcription (
<text@id>) avec une extension média : comme « .mp4 » pour des fichiers vidéos ou « .mp3 » pour des fichiers audio. Par exemple, ajouter le fichier vidéo « transcription01.mp4 » correspondant à la transcription « transcription01.trs ».
À l’exécution du module d’import, le dossier « media » sera transféré dans le corpus binaire (de chemin $TXMHOME/corpora/<identifiant corpus>/media), ce qui permettra à la stratégie par défaut d’accès aux fichiers média de fonctionner directement.
10.4.6.2 Méthode 2. Ajouter des fichiers média dans le corpus binaire
Si les fichiers média sont trop lourds à manipuler pour l’opération précédente, il est possible de ne pas équiper le dossier des sources en amont du module d’import.
Dans ce cas on pourra créer soi-même le dossier $TXMHOME/corpora/<identifiant corpus>/media dans le corpus binaire après import, et y déposer les fichiers médias avec le même format que décrit précédemment.
Pour TXM il n’y aura pas de différence entre des fichiers média copiés depuis les sources et des fichiers médias déposés dans le corpus binaire après import.
10.4.6.3 Méthode 3. Configurer les paramètres d’accès aux fichiers médias du corpus
Si on souhaite utiliser un mode d’accès aux fichiers média différent de la stratégie d’accès par défaut, il suffit de n’importer que les transcriptions avec le module d’import « XML Transcriber + CSV ».
On pourra ensuite modifier les paramètres d’accès aux fichiers médias du corpus créé en suivant les instructions de la section 10.4.5.1 « Paramètres d’accès aux fichiers médias ».
Dans ce cas, quand on exporte le corpus pour le transférer, il faudra bien faire attention à ce que le TXM qui chargera le corpus ai bien accès aux fichiers média au moment de l’utilisation du corpus. Pour un accès distant par site web cela se fera automatiquement.
10.4.7 Corpus exemple P1S8 prêt à l’emploi
TBD
Le corpus exemple P1S8 4 avril 2014, transcription et enregistrement d’un cours de physique en Lycée (cours sur la lumière), est directement utilisable avec l’extension Media Player.
Exemple de mise en oeuvre :
télécharger puis charger le corpus binaire ’P1S8-2023-06-23.txm’ dans TXM
lancer la concordance de ’néon’
faire un retour au média avec la commande “Jouer le media” depuis le menu contextuel de la la 2ième ligne de la concordance
P1S8-30-avril-2014-trimmed, P, 0:00:22 si vous faites taper la lumière d'un néon sur un CD vous ne verrez pas toutes les couleurs de l'
10.5 Extension « XML Editor »
TBD
L’extension « XML Editor » ajoute un éditeur de fichiers XML à TXM[93].
Cet éditeur se lance actuellement sur un fichier pré-existant sur le disque dur, avec la commande « Fichier / Ouvrir un fichier XML… ».
10.5.1 Services du mode syntaxique XML
10.5.1.1 Repérage au sein de la syntaxe XML
Colorisation
Les différents éléments XML sont mis en évidence par une couleur propre pour faciliter le repérage ainsi que la détection d’erreurs de syntaxe :
- <nom de balise> vert turquoise
- nom d’attribut= violet
- “valeur d’attribut” bleu foncé
- <!– commentaires –> bleu clair
- etc.
Par exemple :
- une valeur d’attribut mal fermée « <span style=“… » provoquera une colorisation bleue du reste de la ligne ;
- un commentaire XML mal fermé « <!– … » provoquera une colorisation bleu clair du reste du fichier.
Les couleurs sont paramétrables dans les préférences de TXM, voir plus bas.
Position dans l’arbre XML
L’enchâssement courant du curseur au sein de la hiérarchie des balises est indiqué par un chemin de fer situé en bas à gauche de la fenêtre de TXM.
Fermeture de portions d’arbre
Des boutons de fermeture/ouverture (⊖/⊕) situés en début de ligne de chaque balise ouvrante permettent de réduire temporairement tout le contenu de l’élément.
10.5.1.2 Saisie assistée d’éléments XML
En fonction du schéma ou de la DTD éventuelle du fichier, de la position du curseur et de ce qui vient d’être saisi, l’éditeur propose automatiquement de compléter la saisie.
Par exemple :
- l’ajout de la balise fermante après la saisie d’une balise ouvrante ;
- l’ajout du guillemet fermant une valeur d’attribut ;
- la complétion du nom d’une balise fermante ;
- etc.
Le copier/coller d’éléments XML est accéléré par une sélection par double-click successifs :
- 1 double-click = sélection de la totalité d’une valeur d’attribut ;
- 2 double-clicks successifs = sélection du nom de l’attribut et de sa valeur ;
- 3 double-clicks successifs = sélection de l’ensemble de la balise ouvrante.
L’éditeur gère un jeu de patrons récurrents de balises à insérer rapidement.
10.5.1.3 Formatage automatique
L’éditeur peut :
indenter automatiquement l’ensemble des balises du document ou seulement la portion sélectionnée → commande « Source > Format » du menu contextuel ;
« nettoyer le document » en corrigeant automatiquement la syntaxe XML → commande « Source > Cleanup Document… » du menu contextuel.
10.5.2 Gestion des déclarations XML
10.5.2.1 Association d’une DTD à un fichier XML
Il est possible, mais pas nécessaire, d’associer une DTD au fichier en cours d’édition.
Dans un fichier XML, la déclaration suivante :
<!DOCTYPE balise-racine PUBLIC “IdDoc” “C:\mesdtd\Doc.dtd”>
associera la DTD d’identifiant public « IdDoc » au fichier.
Le chemin d’accès au fichier de DTD est obtenu par le biais du catalogue XML s’il définit l’identifiant « IdDoc » ou directement à partir de la déclaration du chemin d’accès « C:\mesdtd\Doc.dtd ».
On peut également réaliser l’association avec la déclaration suivante :
<!DOCTYPE balise-racine SYSTEM “IdDoc.dtd”>
associant la DTD d’identifiant système « IdDoc.dtd » au fichier. L’identifiant système « IdDoc.dtd » doit alors être déclaré dans le catalogue XML.
10.5.2.2 Association d’un schéma à un fichier XML
Dans un fichier XML, la déclaration suivante :
<document xmlns=“http://txm.org”>
> xsi:schemaLocation=“http://textometrie.org/
> C:\messchemas\document.xsd”>
> <corps>
> …
indiquera le chemin d’accès au fichier de schéma XML directement au processeur XML par le biais de l’attribut xsi:schemaLocation.
On peut également réaliser l’association avec la déclaration suivante :
<document
xmlns=“http://txm.org”
xsi:schemaLocation=“http://textometrie.org document.xsd”>
<corps>
…
associant le schéma d’identifiant système « document.xsd » au fichier. L’identifiant système « document.xsd » doit alors être déclaré dans le catalogue XML.
10.5.2.3 Accès distant aux DTD et schéma XML
Dans le cas d’une déclaration distante comme :
<!DOCTYPE balise-racine PUBLIC “IdDoc” “http://textometrie.org/xml/catalog/dtd/Doc.dtd”>
Si vous êtes connecté à Internet par le biais d’un pare-feu et que vous ne pouvez pas établir votre configuration SOCKS, vous devez télécharger les fichiers vous-même et les installer sur votre machine, puis utiliser des déclarations locales.
10.5.3 Paramétrage de la colorisation des balises XML
Il est possible de régler le style d’affichage des différents types d’éléments XML par le biais des préférences « XML > XML Files > Editor > Syntax coloring ». Pour chaque type d’élément, il est possible de choisir sa couleur d’affichage, celle de son arrière plan ainsi que sa mise en gras éventuelle. Pour rétablir le style par défaut d’un type d’élément, on peut le sélectionner dans le champ « Syntax Element » et cliquer sur « Restore Default ».
Voir aussi la page wikipedia d’Universal Dependencies↩︎
CoNLL-U est le format de fichier utilisé par le projet Universal Dependencies (fichiers d’extension ’‘.conllu’ pour TXM). Chaque mot y est encodé sur une ligne et chaque colonne encode une information syntaxique particulière : numéro du mot dans la phrase, mot gouverneur, relation de dépendance au gouverneur, etc.↩︎
La phrase syntaxique est déterminée par l’analyse syntaxique (autour du mot racine) alors que la phrase orthographique est déterminée par la ponctuation forte ou l’encodage XML. Selon le corpus, ces informations peuvent ne pas correspondre.↩︎
les propriétés
ud-uposetud-lemmasont indépendantes des propriétésfrposetfrlemmacalculées par TreeTagger.↩︎identique à
worddans le cas d’un import CoNLL-U+CSV.↩︎par exemple, les valeurs de l’attribut
@iddes éléments<w>lors des importations d’annotations syntaxiques (e.g.XmlId=w_text-id_325).↩︎nous cherchons la forme car son lemme peut parfois être complexe dans les treebanks UD (eg ‘il’, ‘le’ et ‘lui’ dans UD-French-PUD).↩︎
le corpus PROFITEROLE-GOLD ne contient que des nsubj, mais les corpus en français contemporain (comme UD-French-PUD) contiennent d’autres fonctions : obj, iobj, obl… >[AL : C’est parce que la forme la plus fréquente est “nos”. J’ai modifié la requête, mais il faut voir ce qui est plus intéressant… On peut chercher “que” qui marche aussi bien pour le français moderne et ancien]↩︎
Le début du blocus de Berlin, Les Actualités Françaises, 15 juillet 1948, INA.↩︎
une URL : Uniform Ressource Locator.↩︎